Kamis, 14 Maret 2019
Ukuran Dispersi Data
Pertemuan Keenam Statistika (UKURAN DISPERSI DATA)
Setelah mempelajari pokok bahasan ini, pembaca diharapkan mampu:
Mendefinisikan dan menjelaskan pengertian dispersi data.
Mendefinisikan dan menjelaskan jenis-jenis ukuran dispersi.
Menghitung dan menggunakan rumus-rumus ukuran dispersi.
Mendefinisikan dan menjelaskan koefisien variasi data.
Mendefinisikan dan menjelaskan keruncingan dan kemiringan kurva.
Mendefiniskan dan menjelaskan jenis-jenis keruncingan (kurtosis) dan kemencengan (skewness) kurva.
Oleh: Rachmat Ferdianto
Pengertian Dispersi
Dalam kehidupan sehari-hari kita sering mendengar orang menyebutkan data statistik. Rata-rata upah karyawan perusahaan Rp.2.000.0000 per bulan, rata-rata jumlah mahasiswa baru Raharja 1000 mahasiswa per tahun ajaran baru. Setiap kali kita mendengar rata-rata, maka secara otomatis kita membayangkan sekelompok nilai di sekitar rata-rata tersebut. Ada yang sama dengan rata-rata, ada yang lebih kecil, dan ada yang lebih besar dari rata-rata tersebut. Dengan kata lain, ada variasi atau dispersi dari nilai-nilai tersebut, baik terhadap nilai lainnya maupun terhadap rata-ratanya. Ukuran dispersi atau ukuran variasi atau ukuran penyimpangan adalah ukuran yang menyatakan seberapa jauh penyimpangan nilai-nilai data dari nilai-nilai pusatnya atau ukuran yang menyatakan seberapa banyak nilai-nilai data yang berbeda dengan nilai-nilai pusatnya.
Ukuran variabilitas adalah sebuah ukuran derajat penyebaran nilai-nilai variabel dari suatu ukuran pemusatan data dalam sebuah distribusi. Dua kelompok distribusi data dapat memiliki nilai ukuran pemusatan yang sama, akan tetapi derajat penyebarannya bisa jadi sangat berbeda. Misalnya kita memiliki data yang berasal dari dua kelompok individu yang berbeda. Data kelompok individu A : 24, 24, 25, 25, 25, 26, 26, diperoleh mean sebesar 25. Dan data dari kelompok individu B : 16, 19, 22, 25, 28, 30, 35, diperoleh mean sebesar 25.
Nilai tendensi sentral dalam dua distribusi A dan B tersebut di atas adalah sama yaitu keduanya memiliki harga rata-rata = 25. Namun demikian apabila dilihat dari keragaman dan penyebaran nilai dari kedua distribussi tersebut tampak sangat berbeda. Dimana penyebaran nilai-nilai dalam distribusi A terlihat lebih homogen dibanding distribusi B. Sebaliknya penyebaran nilai dalam distribusi B lebih beragam atau heterogen dibanding penyebaran nilai dalam distribusi A. Hal ini diperlukan suatu indeks yang tidak saja dapat memberikan gambaran ringkas mengenai suatu distribusi (melalui suatu ukuran pemusatan data atau ukuran tendensi sentral), melainkan juga diperlukan suatu ukuran yang dapat memberikan gambaran berdasarkan keragaman nilai-nilai dalam suatu distribusi.
Ukuran dispersi pada dasarnya adalah pelengkap dari ukuran nilai pusat dalam menggambarkan sekumpulan data. Jadi, dengan adanya ukuran dispersi maka penggambaran sekumpulan data akan menjadi lebih jelas dan tepat. Ada beberapa macam ukuran variasi atau dispersi, misalnya nilai jarak (range), rata-rata simpangan (mean deviation), simpangan baku (standard deviation), koefisien variasi (coefficient of variation), ukuran kemencengan kurva (skewness), dan ukuran keruncingan kurva (kurtosis). Di antara ukuran variasi atau disperse data tersebut simpangan baku yang sering dipergunakan, khususnya untuk keperluan analisis data.
JENIS-JENIS UKURAN DISPERSI
Jangkauan (Range, R)
Jangkauan atau ukuran jarak adalah selisih nilai terbesar data dengan nilai terkecil data. Dengan kata lain range atau disebut juga rentangan atau jarak pengukuran dapat didefinisikan sebagai jarak antara nilai tertinggi dengan nilai terendah. Besar kecilnya range dapat digunakan sebagai petunjuk untuk mengetahui taraf keragaman dan variabilitas suatu distribusi. Semakin tinggi range berarti distribusinya semakin beragam, bervariasi atau heterogen. Sebaliknya semakin kecil harga range maka distribusinya semakin tidak bervariasi, tidak beragam, sejenis atau homogen.
Walaupun prosedur yang dilalui sangat sederhana, namun penggunaan range sebagai ukuran variabilitas harus dilakukan dengan hati-hati. Karena range sangat bergantung pada data yang ekstrim (yaitu data yang kemunculan dan ketidak munculannya sangat berpengaruh pada tinggi rendahnya nilai range). Oleh karena hanya didasarkan pada dua nilai yang tertinggi dan terendah inilah, maka range merupakan indeks variabilitas yang tidak dapat diandalkan, tidak stabil atau tidak mantap (reliable) sebagai pendekatan metodologi ilmiah. Cara mencari jangkauan dibedakan antara data tunggal dan data berkelompok.
Jangkauan data tunggal
Bila ada sekumpulan data tunggal X1, X2, …, Xn maka jangkauannya adalah
Jangkauan
Contoh :
Tentukan jangkauan data: 1, 4, 7, 8, 9, 11 !
Jawab:
X6 = 11 dan X1 = 1
Jangkauan =
Jangkauan data berkelompok
Untuk data berkelompok, jangkauan dapat ditentukan dengan dua cara, yaitu menggunakan titik atau nilai tengah dan menggunakan tepi kelas. Jangkauan adalah selisih titik tengah kelas tertinggi dengan titik tengah kelas terendah. Jangkauan adalah selisih tepi atas kelas tertinggi dengan tepi bawah kelas terendah.
Contoh :Tentukan jangkauan dari distribusi frekuensi berikut!
Tabel 4.1. Hasil Pengukuran Tinggi Badan 50 Mahasiswa STMIK Raharja
Tinggi Badan (cm)
Frekuensi
140 – 144
145 – 149
150 – 154
155 – 159
160 – 164
165 – 169
170 – 174
2
4
10
14
12
5
3
Jumlah
50
Jawab:
Dari Tabel 4.1. terlihat bahwa:
Titik tengah kelas terendah = 142
Titik tengah kelas tertinggi = 172
Tepi bawah kelas terendah = 139,5
Tepi atas kelas tertinggi = 174,5
Jangkauan = 172 – 142 = 30
Jangkauan = 174,5 – 139,5 = 35
Jangkauan Semi Interkuartil
Jangkauan antarkuartil adalah selisih antara nilai kuartil atas dan kuartil bawah Dirumuskan:
Jangkauan semi interkuartil atau simpangan kuartil (deviasi kuartil) dari suatu himpunan data, disimbolkan dengan Q didefinisikan sebagai setengah dari selisih kuartil dengan kuartil bawah . Dirumuskan:
Di mana Q1 dan Q2 adalah kuartil pertama dan kuartil ketiga dari kelompok data. Jangkauan interkuartil kadang-kadang digunakan juga meskipun jaangkauan semi interkuartil lebih umum dan sering digunakan sebagai ukuran untuk disperse data. Rumus-rumus di atas berlaku baik untuk data tunggal dan data yang telah dikelompokan dalam distribusi frekuensi. Perhatikan contoh berikut:
Tentukan jangkauan antarkuartil dan jangkauan semi interkuartil dari data berikut!
2, 4, 6, 8, 10, 12, 14
Jawab:
dan
Tentukan jangkauan antarkuartil dan jangkauan semi interkuartil berikut!
Tabel 4.2. Nilai Statistik 80 Mahasiswa STMIK Raharja Semester II.
Nilai
Frekuensi
30 – 39
40 – 49
50 – 59
60 – 69
70 – 79
80 – 89
90 – 99
2
3
5
14
24
20
12
Jumlah
80
Jawab:
Jangkauan antarkuartil (JK) dapat digunakan untuk menemukan adanya data pencilan, yaitu data yang dianggap salah catat atau salah ukur atau berasal dari kasus yang menyimpang, karena itu perlu diteliti ulang. Data pencilan adalah data yang kurang dari pagar dalam atau lebih dari pagar luar.
Keterangan:
Satu langkah pagar dalam pagar luar
Contoh : Selidiki apakah terdapat data pencilan dari data di bawah ini!
15, 33, 42, 50, 51, 51, 53, 55, 62, 64, 65, 68, 79, 85, 97
Jawab: dan
Pada data di atas terdapat nilai 15 dan 97 yang berarti kurang dari pagar dalam (23) atau lebih dari pagar luar (95). Dengan demikian, nilai 15 dan 97 termasuk data pencilan, karena itu perlu diteliti ulang. Adanya nilai 15 dan 97 mungkin disebabkan salah dalam mencatat, salah dalam mengukur, atau data dari kasus yang menyimpang.
Deviasi Rata-Rata (Simpangan Rata-Rata)
Deviasi rata-rata atau deviasi mean disingkat MD (mean deviation) dari himpunan data didefinisikan sebagai nilai rata-rata hitung dari harga mutlak simpangan-simpangannya. Dengan kata lain, untuk melakukan penghitungan MD digunakan harga yang mutlak saja, yaitu dengan hanya menggunakan nilai-nilai yang bertanda positif saja sedangkan nilai-nilai yang memiliki tanda negatif tidak diperhitungkan atau diabaikan. Cara mencari deviasi rata-rata, dibedakan antara data tunggal dan data berkelompok.
Deviasi rata-rata data tunggal
Untuk data tunggal, deviasi rata-ratanya dapat dihitung dengan menggunakan rumus:
Contoh : Tentukan deviasi rata-rata dari 2, 3, 6, 8, 11!
Jawab:
Rata-rata hitung
Deviasi rata-rata untuk data berkelompok
Untuk data berkelompok (distribusi frekuensi), deviasi rata-ratanya dapat dihitung dengan rumus:
Contoh:
Tentukan deviasi rata-rata dari distribusi frekuensi pada Tabel 4.1.!
Jawab:
Dari Tabel 4.1. didapat Dengan nilai itu, dapat dibuat tabel deviasinya.
Tinggi Badan (cm)
140 – 144
145 – 149
150 – 154
155 – 159
160 – 164
165 – 169
170 – 174
142
147
152
157
162
167
172
2
4
10
14
12
5
3
15,7
10,7
5,7
0,7
4,3
9,3
14,3
31,4
42,8
57
9,8
51,6
46,5
42,9
Jumlah
–
50
–
282
Oleh karena MD ini mengabaikan tanda-tanda plus minus maka tidaak dapat diteruskan kepada perhitungan-perhitungan matematik lebih lanjut, terutama pada rumus-rumus yang mencantumkan tanda plus minus itu. Untuk mengatasi kelemahan ini, digunakan cara perhitungan ukuran variabilitas yang lain, yaitu yang dikenal dengan simpangan baku atau standar deviasi atau deviasi standar. Namun sebelum masuk ke pembahasan standar deviasi akan diuraikan terlebih dahulu tentang varians.
Variansi (Variance)
Seperti pada perhitungan simpangan rata-rata, variasi juga menggunakan selisih atau simpangan antara semua nilai data dengan rata-rata hitung. Bedanya pada rumus simpangan rata-rata yang digunakan adalah nilai mutlak dari selisih nilai, sedangkan pada variansi yang digunakan adalah kuadrat selisih nilai. Walaupun nilai mutlak dan kuadrat sama-sama bertujuan untuk membuat nilai negatif menjadi positif, tetapi maknanya sangat berbeda dan mempunyai pengaruh yang berbeda terhadap ukuran dispersi data. Varians adalah nilai tengah kuadrat simpangan dari nilai tengah atau simpangan rata-rata kuadrat. Untuk sampel, variansnya (varians sampel) disimbolkan dengan Untuk populasi, variansnya (varians populasi) disimbolkan dengan (baca: sigma).
Varians data tunggal
Untuk seperangkat data X1, X2, X3,…, Xn (data tunggal), variansnya dapat ditentukan dengan dua metode, yaitu metode biasa dan metode angka kasar.
Metode biasa
Untuk sampel besar
Untuk sampel kecil
Metode angka kasar
Untuk sampel besar
Untuk sampel kecil
Contoh: Tentukan varians dari data 2, 3, 6, 8, 11!
Jawab: maka diperoleh
2
3
6
8
11
-4
-3
0
2
5
16
9
0
4
25
4
9
36
64
121
30
54
234
Varians data berkelompok
Untuk data berkelompok (data yang telah dikelompokan dalam distribusi frekuensi), variansnya dapat ditemukan dengan menggunakan tiga metode, yaitu metode biasa, metode angka kasar, dan metode coding.
Metode biasa
Untuk sampel besar
Untuk sampel kecil
Metode angka kasar
Untuk sampel besar
Untuk sampel kecil
Metode coding
Untuk sampel besar
Untuk sampel kecil
Keterangan:
panjang interval kelas
rata-rata hitung sementara.
Contoh : Tentukan varians dari distribusi frekuensi berikut!
Tabel 4.3. Hasil Pengukuran Diameter Pipa
Diameter
Frekuensi
65 – 67
68 – 70
71 – 73
74 – 76
77 – 79
80 – 82
2
5
13
14
4
2
Jumlah
40
Jawab:
Dengan menggunakan metode biasa:
Diameter
65 – 67
68 – 70
71 – 73
74 – 76
77 – 79
80 – 82
66
69
72
75
78
81
2
5
13
14
4
2
-7,425
-4,425
-1,425
1,575
4,575
7,575
55,131
19,581
2,031
2,481
20,931
57,381
110,262
97,905
26,403
34,734
83,724
114,762
Jumlah
–
40
–
–
467,790
Dengan metode angka kasar:
Diameter
65 – 67
68 – 70
71 – 73
74 – 76
77 – 79
80 – 82
66
69
72
75
78
81
2
5
13
14
4
2
4.356
4.761
5.184
5.625
6.084
6.561
132
345
936
1.050
312
162
8.712
23.805
67.392
78.750
24.336
13.122
Jumlah
–
40
–
2.937
216.117
Dengan metode coding:
Diameter
65 – 67
68 – 70
71 – 73
74 – 76
77 – 79
80 – 82
66
69
72
75
78
81
2
5
13
14
4
2
-3
-2
-1
0
1
2
9
4
1
0
1
4
-6
-10
-13
0
4
4
18
20
13
0
4
8
Jumlah
–
40
–
-21
63
Hasil perhitungan dengan menggunakan ketiga rumus adalah sama, namun dengan menggunakan rumus ke-3, perhitungannya jauh lebih sederhana dan cepat. Perhatikan bahwa dengan menggunakan varians, disperse data tersebut jauh lebih besar jika dibandingkan dengan menggunakan simpangan rata-rata. Hal ini diakibatkan oleh variansi yang menggunakan kuadrat selisih nilai-nilai data terhadap rata-rata hitung, sehingga simpangannya membesar secara drastis. Ini berarti varians bukan merupakan ukuran dispersi yang baik untuk menggambarkan penyebaran data. Kelemahan varians disebabkan oleh bentuk kuadrat yang dipakai dalam rumus, sementara dispersi data sesungguhnya merupakan ukuran yang bentuknya linier. Oleh karena itu varians juga jarang digunakan dalam analisis data. Namun demikian, variansi masih mempunyai kelebihan karena melibatkan selisih dari semua nilai data.
Varians gabungan
Misalkan, terdapat buah subsample sebagai berikut:
– Sub-sampel 1, berukuran dengan varians
– Sub-sampel 2, berukuran dengan varians
– ……………., ………… ……… ……
– Sub-sampel berukuran dengan varians
Jika subsampel-subsampel tersebut digabungkan menjadi sebuah sampel berukuran , maka varians gabungannya adalah:
atau
Contoh: Hasil pengamatan terhadap 20 objek mendapatkan s = 4. Pengamatan
terhadap 30 objek mendapatkan s = 5. Berapakah varians gabungannya?
Ukuran data sudah dikelompokan
UKURAN GEJALA PUSAT
Ukuran gejala pusat merupakan suatu bilangan yang menunjukan sekitar dimana bilangan – bilangan yang ada dalam kumpulan data, oleh karenanya ukuran gejala pusat ini sering disebut dengan harga rata – rata. Harga rata – rata dari sekelompok data itu diharapkan dapat diwakili seluruh harga – harga yang ada dalam sekelompok data itu.
Sebelum membahas hal ini, perlu diperjelas tentang apa yang dimaksud dengan data yang dikelompokkan dan data yang tidak dikelompokkan. Data yang dikelompokkan adalah data yang sudah disusun ke dalam sebuah distribusi frekuensi sehingga data tersebut mempunyai interval kelas yang jelas, mempunyai titik tengah kelas sedangkan data yang tidak dikelompokkan adalah data yang tidak disusun ke dalam distribusi frekuensi sehingga tidak mempunyai interval kelas dan titik tengah kelas.
Mean, Median, Modus sama-sama merupakan ukuran pemusatan data yang termasuk kedalam analisis statistika deskriptif. Namun, ketiganya memiliki kelebihan dan kekurangannya masing-masing dalam menerangkan suatu ukuran pemusatan data. Untuk tahu kegunaannya masing-masing dan kapan kita mempergunakannya, perlu diketahui terlebih dahulu pengertian analisis statistika deskriptif dan ukuran pemusatan data.
a. Mean (Rata – Rata Hitung)
Dalam istilah sehari – hari, mean dikenal dengan sebutan angka rata – rata, ada dua macam mean yang di bicarakan yaitu : mean untuk data yang tidak dikelompokkan dan mean untuk data yang dikelompokan. Mean adalah total semua data dibagi jumlah data. Mean digunakan ketika data yang kita miliki memiliki sebaran normal atau mendekati normal (berbentuk setangkup, nilai yang paling banyak berada ditengah dan makin besar semakin sedikit, makin kecil makin sedikit pula, nilai-nilai ekstrim yang besar maupun yang kecil hampir tidak ada).
b. Median (Nilai Tengan)
Ukuran pemusatan yang menempati posisi tengah jika data diurutkan menurut besarnya. Median adalah nilai yang berada ditengah-tengah data setelah diurutkan dari yang terkecil sampai terbesar. Median cocok digunakan bila data yang kita miliki tidak menyebar normal atau memiliki nilai yang berbeda-beda secara signifikan.
c. Modus (Data Yang Sering Muncul)
Modus adalah suatu angka atau bilangan yang paling sering terjadi / muncul tetapi kalo pada data distribusi frekuensi interval modus terletak pada frekuensi yang paling besar.
d. Kuartil
Kuartil adalah suatu harga yang membagi histogram frekuensi menjadi 4 bagian yang sama, sehingga disini akan terdapat 3 harga kuartil yaitu kuartil I ( K1), kuartil II (K2) dan kuartil III (K3), dimana harga kuarti II sama dengan harga median.
e. Desil
Untuk kelompok data dimana n ≥ 10, dapat ditentukan 9 nilai bagian yang sama, misalnya D1, D2, … Q9, artinya setiap bagian mempunyai jumlah observasi yang sama, sedemikian rupa sehingga nilai 10% data/observasi sama atau lebih kecil dari D1, nilai 20% data/observasi sama atau lebih kecil dari D2, dan seterusnya. Nilai tersebut dinamakan desil pertama, kedua dan seterusnya sampai desil kesembilan.
f. Persentil
Untuk kelompok data dimana n ≥ 100, dapat ditentukan 99 nilai, P1, P2, … P99, yang disebut persentil pertama, kedua dan ke-99, yang membagi kelompok data tersebut menjadi 100 bagian,masing-masing mempunyai bagian dengan jumlah observasi yang sama, dan sedemikian rupa sehingga 1% data/observasi sama atau lebih kecil dari P1, 2% data/observasi sama atau lebih kecil dari P2.
UKURAN VARIASI (DISPERSI)
Dispersi atau variasi atau keragaman data adalah ukuran penyebaran suatu kelompok data terhadap pusat data.
a. Range
Range merupakan selisih antara nilai data terbesar dengan data terkecil dari sekelompok data.
Rumusannya adalah R = Nilai maksimal – Nilai minimal
b. Simpangan rata-rata
Simpangan Rata-Rata (Sr) : Yang dimaksud dengan simpangan (deviation) adalah selisih antara nilai pengamatan ke-i dengan nilai rata-rata, atau antara xi dengan X (X Rata-Rata) Penjumlahan daripada simpangan-simpangan dalam pengamatan kemudian dibagi dengan jumlah pengamatan, n, disebut dengan simpangan rata-rata.
Dalam setiap nilai Xi akan mempunyai simpangan sebesar xi - X. Karena nilai xi bervariasi di atas dan di bawah nilai rata-ratanya maka jika nilai simpangan tersebut dijumlahkan akan sama dengan “nol”. Untuk dapat menghitung rata-rata dari simpangan tersebut maka nilai yang diambil adalah nilai “absolut” dari simpangan itu sendiri, artinya tidak menghiraukan apakah nilai simpangan tersebut positif (+) atau negatif (-).an rata-rata.
c. Variansi (variance)
Variansi (variance) adalah rata-rata kuadrat selisih atau kuadrat simpangan dari semua nilai data terhadap rata-rata hitung. Varians untuk sampel dilambangkan dengan S2. Sedangkan untuk populasi dilambangkan dengan toh kuadrat .
d. Simpangan Baku (Standard Deviation)
Standar deviasi (standard deviation) adalah akar pangkat dua dari variansi. Standar deviasi seringkali disebut sebagai simpangan baku.
e. Jangkauan Kuartil
Jangkauan Kuartil atau simpangan kuartil adalah setengah dari selisih antara kuartil atas (Q3) dengan kuartil bawah (Q1). Dengan rumus :
JK=1/2 (Q3-Q1)
f. Jangkauan Persentil
Jangkauan Persentil adalah selisih antara persentil ke-90 dengan persentil ke-10. Dengan rumus :
JP (10-90) = P90-P10
Data sekunder
Sample data sekunder yang kami ambil yaitu jumlah penduduk kota Bogor tahun 2006 yang dikelompokan berdasarkan pembagian kecamatan dan berdasarkan jenis kelamin.
Sampel datanya ada sebagai berikut :
JUMLAH PENDUDUK KOTA BOGOR PER KECAMATAN
MENURUT JENIS KELAMIN TAHUN 2006
Kecamatan
Laki-Laki
Perempuan
Jumlah
Bogor Selatan
77.254
73.881
151.135
Bogor Timur
38.307
38.958
77.265
Bogor Utara
64.148
61.710
125.858
Bogor Barat
86.496
84.148
170.644
Bogor Tengah
60.235
60.235
120.470
Tanah Sareal
83.257
49.236
132.493
Jumlah
409.427
368.168
777.865
Data Yang Sudah Dikelompokan :
JUMLAH PENDUDUK
(Dalam Ratusan)
f
Fkum
Mi
FiMi
µ
Mi - µ
(Mi µ)2
F(Mi - µ)2
38,5 – 47,5
2
43
2
64
26,25
16,75
280,57
561,14
48,5 – 57,5
1
53
3
53
26,25
26,75
715,57
715,57
58,5 – 67,5
4
63
7
252
26,25
36,75
1350,57
5402,28
68,5 – 77,5
2
73
9
146
26,25
46,75
2185,57
4371,14
78,5 – 87,5
3
83
12
249
26,25
56,75
3220,57
9661,71
Jumlah
12
315
12
20711,84
Ø Mean X = FiMi
∑Fi
= 315
12
= 26,25
Ø Median = tbmed + (n/2 – Fk) . c
f
= 57,55 + (6 – 7) . 10
4
= 57,55 + (-10)
4
= 57,55 + (-2,5)
= 55,05
Ø Modus = tbmod + d1 . c
d2 + d1
= 57,55 + 3 . 10
3 + 2
= 57,55 + 30
5
= 57,55 + 6
= 63,55
Ø Kuartil
Kuartil dari data di atas :
Q1 = 1(12) = 12 = 3
4 4
Q1 = tbQ + (1.n/4 - ∑fkum) . c
fQ
= 67,55 + (3 – 7) . 10
2
= 67,55 + (-40)
2
= 67,55 + (-20)
= 47,55
Q3 = 3(12) = 36 = 9
4 4
Q3 = tbQ + (1.n/4 - ∑fkum) . c
fQ
= 87,55 + (9 – 12) . 10
3
= 87,55 + (-30)
3
= 87,55 + (-10)
= 77,55
Ø Desil
Desil dari data di atas :
iN = 12 = 1,2
10 10
Ø Persentil
Persentil dari data di atas :
iN = 12 = 0,12
100 100
Ø Simpangan rata-rata (Mean Deviation)
Simpangan rata-rata dari data di atas :
SR = 1 ∑f x x
n
= 183,75
12
= 15,31
Ø Simpangan (Varian)
Varian dari data di atas :
S2 = 1 ∑f(X – Mi)2
n – 1
= 20711,84
11
= 1882,90
Ø Simpangan Baku
Simpangan Baku dari data di atas :
S = √S2
= √1882,90
=43,39
Ø Jangkauan Kuartil
Jangkauan Kuartil dari data di atas :
JK = ½(Q3 – Q1)
= ½(77,55 – 47,55)
= ½(30)
= 15
Ø Jangkauan Persentil
Jangkauan Persentil dari data di atas :
P90 = 90 x 12 = 10,8
100
P10 = 10 x 12 = 1,2
100
JP90-10 = P90 – P10
= 10,8 – 1,2
= 9,6
Ukuran gejala pusat merupakan suatu bilangan yang menunjukan sekitar dimana bilangan – bilangan yang ada dalam kumpulan data, oleh karenanya ukuran gejala pusat ini sering disebut dengan harga rata – rata. Harga rata – rata dari sekelompok data itu diharapkan dapat diwakili seluruh harga – harga yang ada dalam sekelompok data itu.
Sebelum membahas hal ini, perlu diperjelas tentang apa yang dimaksud dengan data yang dikelompokkan dan data yang tidak dikelompokkan. Data yang dikelompokkan adalah data yang sudah disusun ke dalam sebuah distribusi frekuensi sehingga data tersebut mempunyai interval kelas yang jelas, mempunyai titik tengah kelas sedangkan data yang tidak dikelompokkan adalah data yang tidak disusun ke dalam distribusi frekuensi sehingga tidak mempunyai interval kelas dan titik tengah kelas.
Mean, Median, Modus sama-sama merupakan ukuran pemusatan data yang termasuk kedalam analisis statistika deskriptif. Namun, ketiganya memiliki kelebihan dan kekurangannya masing-masing dalam menerangkan suatu ukuran pemusatan data. Untuk tahu kegunaannya masing-masing dan kapan kita mempergunakannya, perlu diketahui terlebih dahulu pengertian analisis statistika deskriptif dan ukuran pemusatan data.
a. Mean (Rata – Rata Hitung)
Dalam istilah sehari – hari, mean dikenal dengan sebutan angka rata – rata, ada dua macam mean yang di bicarakan yaitu : mean untuk data yang tidak dikelompokkan dan mean untuk data yang dikelompokan. Mean adalah total semua data dibagi jumlah data. Mean digunakan ketika data yang kita miliki memiliki sebaran normal atau mendekati normal (berbentuk setangkup, nilai yang paling banyak berada ditengah dan makin besar semakin sedikit, makin kecil makin sedikit pula, nilai-nilai ekstrim yang besar maupun yang kecil hampir tidak ada).
b. Median (Nilai Tengan)
Ukuran pemusatan yang menempati posisi tengah jika data diurutkan menurut besarnya. Median adalah nilai yang berada ditengah-tengah data setelah diurutkan dari yang terkecil sampai terbesar. Median cocok digunakan bila data yang kita miliki tidak menyebar normal atau memiliki nilai yang berbeda-beda secara signifikan.
c. Modus (Data Yang Sering Muncul)
Modus adalah suatu angka atau bilangan yang paling sering terjadi / muncul tetapi kalo pada data distribusi frekuensi interval modus terletak pada frekuensi yang paling besar.
d. Kuartil
Kuartil adalah suatu harga yang membagi histogram frekuensi menjadi 4 bagian yang sama, sehingga disini akan terdapat 3 harga kuartil yaitu kuartil I ( K1), kuartil II (K2) dan kuartil III (K3), dimana harga kuarti II sama dengan harga median.
e. Desil
Untuk kelompok data dimana n ≥ 10, dapat ditentukan 9 nilai bagian yang sama, misalnya D1, D2, … Q9, artinya setiap bagian mempunyai jumlah observasi yang sama, sedemikian rupa sehingga nilai 10% data/observasi sama atau lebih kecil dari D1, nilai 20% data/observasi sama atau lebih kecil dari D2, dan seterusnya. Nilai tersebut dinamakan desil pertama, kedua dan seterusnya sampai desil kesembilan.
f. Persentil
Untuk kelompok data dimana n ≥ 100, dapat ditentukan 99 nilai, P1, P2, … P99, yang disebut persentil pertama, kedua dan ke-99, yang membagi kelompok data tersebut menjadi 100 bagian,masing-masing mempunyai bagian dengan jumlah observasi yang sama, dan sedemikian rupa sehingga 1% data/observasi sama atau lebih kecil dari P1, 2% data/observasi sama atau lebih kecil dari P2.
UKURAN VARIASI (DISPERSI)
Dispersi atau variasi atau keragaman data adalah ukuran penyebaran suatu kelompok data terhadap pusat data.
a. Range
Range merupakan selisih antara nilai data terbesar dengan data terkecil dari sekelompok data.
Rumusannya adalah R = Nilai maksimal – Nilai minimal
b. Simpangan rata-rata
Simpangan Rata-Rata (Sr) : Yang dimaksud dengan simpangan (deviation) adalah selisih antara nilai pengamatan ke-i dengan nilai rata-rata, atau antara xi dengan X (X Rata-Rata) Penjumlahan daripada simpangan-simpangan dalam pengamatan kemudian dibagi dengan jumlah pengamatan, n, disebut dengan simpangan rata-rata.
Dalam setiap nilai Xi akan mempunyai simpangan sebesar xi - X. Karena nilai xi bervariasi di atas dan di bawah nilai rata-ratanya maka jika nilai simpangan tersebut dijumlahkan akan sama dengan “nol”. Untuk dapat menghitung rata-rata dari simpangan tersebut maka nilai yang diambil adalah nilai “absolut” dari simpangan itu sendiri, artinya tidak menghiraukan apakah nilai simpangan tersebut positif (+) atau negatif (-).an rata-rata.
c. Variansi (variance)
Variansi (variance) adalah rata-rata kuadrat selisih atau kuadrat simpangan dari semua nilai data terhadap rata-rata hitung. Varians untuk sampel dilambangkan dengan S2. Sedangkan untuk populasi dilambangkan dengan toh kuadrat .
d. Simpangan Baku (Standard Deviation)
Standar deviasi (standard deviation) adalah akar pangkat dua dari variansi. Standar deviasi seringkali disebut sebagai simpangan baku.
e. Jangkauan Kuartil
Jangkauan Kuartil atau simpangan kuartil adalah setengah dari selisih antara kuartil atas (Q3) dengan kuartil bawah (Q1). Dengan rumus :
JK=1/2 (Q3-Q1)
f. Jangkauan Persentil
Jangkauan Persentil adalah selisih antara persentil ke-90 dengan persentil ke-10. Dengan rumus :
JP (10-90) = P90-P10
Data sekunder
Sample data sekunder yang kami ambil yaitu jumlah penduduk kota Bogor tahun 2006 yang dikelompokan berdasarkan pembagian kecamatan dan berdasarkan jenis kelamin.
Sampel datanya ada sebagai berikut :
JUMLAH PENDUDUK KOTA BOGOR PER KECAMATAN
MENURUT JENIS KELAMIN TAHUN 2006
Kecamatan
Laki-Laki
Perempuan
Jumlah
Bogor Selatan
77.254
73.881
151.135
Bogor Timur
38.307
38.958
77.265
Bogor Utara
64.148
61.710
125.858
Bogor Barat
86.496
84.148
170.644
Bogor Tengah
60.235
60.235
120.470
Tanah Sareal
83.257
49.236
132.493
Jumlah
409.427
368.168
777.865
Data Yang Sudah Dikelompokan :
JUMLAH PENDUDUK
(Dalam Ratusan)
f
Fkum
Mi
FiMi
µ
Mi - µ
(Mi µ)2
F(Mi - µ)2
38,5 – 47,5
2
43
2
64
26,25
16,75
280,57
561,14
48,5 – 57,5
1
53
3
53
26,25
26,75
715,57
715,57
58,5 – 67,5
4
63
7
252
26,25
36,75
1350,57
5402,28
68,5 – 77,5
2
73
9
146
26,25
46,75
2185,57
4371,14
78,5 – 87,5
3
83
12
249
26,25
56,75
3220,57
9661,71
Jumlah
12
315
12
20711,84
Ø Mean X = FiMi
∑Fi
= 315
12
= 26,25
Ø Median = tbmed + (n/2 – Fk) . c
f
= 57,55 + (6 – 7) . 10
4
= 57,55 + (-10)
4
= 57,55 + (-2,5)
= 55,05
Ø Modus = tbmod + d1 . c
d2 + d1
= 57,55 + 3 . 10
3 + 2
= 57,55 + 30
5
= 57,55 + 6
= 63,55
Ø Kuartil
Kuartil dari data di atas :
Q1 = 1(12) = 12 = 3
4 4
Q1 = tbQ + (1.n/4 - ∑fkum) . c
fQ
= 67,55 + (3 – 7) . 10
2
= 67,55 + (-40)
2
= 67,55 + (-20)
= 47,55
Q3 = 3(12) = 36 = 9
4 4
Q3 = tbQ + (1.n/4 - ∑fkum) . c
fQ
= 87,55 + (9 – 12) . 10
3
= 87,55 + (-30)
3
= 87,55 + (-10)
= 77,55
Ø Desil
Desil dari data di atas :
iN = 12 = 1,2
10 10
Ø Persentil
Persentil dari data di atas :
iN = 12 = 0,12
100 100
Ø Simpangan rata-rata (Mean Deviation)
Simpangan rata-rata dari data di atas :
SR = 1 ∑f x x
n
= 183,75
12
= 15,31
Ø Simpangan (Varian)
Varian dari data di atas :
S2 = 1 ∑f(X – Mi)2
n – 1
= 20711,84
11
= 1882,90
Ø Simpangan Baku
Simpangan Baku dari data di atas :
S = √S2
= √1882,90
=43,39
Ø Jangkauan Kuartil
Jangkauan Kuartil dari data di atas :
JK = ½(Q3 – Q1)
= ½(77,55 – 47,55)
= ½(30)
= 15
Ø Jangkauan Persentil
Jangkauan Persentil dari data di atas :
P90 = 90 x 12 = 10,8
100
P10 = 10 x 12 = 1,2
100
JP90-10 = P90 – P10
= 10,8 – 1,2
= 9,6
Mudah belajar ukuran data belum di kelompokan
UKURAN GEJALA PUSAT DATA YANG BELUM DIKELOMPOKKAN
Landasan Teori
Pengertian Distribusi Frekuensi
Distribusi frekuensi adalah suatu bentuk penyusunan data yang teratur dengan menggolongkan besar atau kecilnya data. Distribusi frekuensi umumnya disajikan dalam daftar yang berisi kelas interval dan jumlah objek (frekuensi) yang termasuk dalam kelas interval tersebut.
Fungsi distribusi frekuensi adalah mengatur data mentah (belum dikelompokkan) ke dalam bentuk yang rapi tanpa mengurangi data yang ada.
Istilah – istilah dalam distribusi frekuensi adalah :
- Kelas
- Batas Kelas
- Tepi Kelas
- Interval Kelas
- Titik Tengah
Contoh Kasus Distribusi Frekuensi
Berikut ini adalah data jumlah pendidik kependidikan menurut usia
27 54
27
28
28
22 45
37
50
38
53 48
55
42
44
40 26
31
26
42
36 42
27
53
36
25 25
24
46
43
54 42
49
35
48
32
Berikut ini cara untuk menggunakan analisis manual :
a) Mengurutkan data
b) Menentukan Range
c) Menentukan Banyaknya Kelas
d) Menentukan Panjang Interval Kelas
e) Menentukan Batas – batas Kelas
f) Menentukan Titik Tengah
a).Mengurutkan Data
22 24 25 25 26
26 26 27 27 27
28 31 32 35 36
36 37 38 40 42
42 42 42 43 44
45 46 48 48 49
50 53 53 54 54
55
b)Menentukan Range (R)
Range adalah selisih antara nilai terbesar dengan nilai terkecil.
Rumus Range adalah :
R = Xmax - Xmin
= 55 – 22
= 33
c). Mencari banyaknya kelas menggunakan rumus Sturges
Kelas adalah penggolongan data yang dibatasi dengan nilai terendah dan nilai tertinggi yang masing - masing dinamakan batas kelas.
K = 1 + 3,3 log N
= 1 + 3,3 log 36
= 1 + 5,13
= 6,13 di bulatkan 7
Jadi banyak kelas = 7
d).Menentukan panjang interval kelas (I)
Interval kelas adalah lebar dari sebuah kelas dan dihitung dari perbedaan antara kedua tepi kelasnya.
I = R / K
= 33 / 7
= 4,71 di bulatkan 5
Jadi nilai interval kelasnya = 5
e).Menentukan Batas Kelas
Batas kelas terbagi menjadi 2 yaitu :
1.Batas bawah kelas (bbk),yaitu nilai data yang di tulis untuk setiap kelas interval
2.Batass atas kelas (bak), yaitu nilai data yang terletak disebelah kanan untuk setiap kelas interval
Contoh ; Misalkan salah satu data Pendidik Kependidikan menurut usia adalah = 22 - 27
Kesimpulan ; Batas bawah kelas = 22
Batas atas kelas = 27
F ).Menentukan Tepi Kelas
Tepi kelas terbagi menjadi dua yaitu :
1.Tepi bawah kelas (tbk) : Batas bawah kelas di kurangi ketelitian data (0,5)
Ø Rumus tbk = bbk – 0,5(skala terkecil)
2.Tepi atas kelas (tak) : Batas atas kelas ditambah ketelitian data (0,5)
Ø Rumus tak = bak + 0,5 (skala terkecil)
g ).Menentukan titik tengah
Titik tengah yaitu setengah kali jumlah batas bawah dan batas atas kelas.
Rumus ½ * (bak + bbk)
Contoh ; data = 22 – 27
Xi = ½ * (22 + 27)
= 24,5
Jenis-jenis Distribusi Frekuensi
a.Distribusi Frekuensi Kumulatif
adalah suatu daftar yang memuat frekuensi – frekuensi kumulatif, jika ingin mengetahui banyaknya observasi yang ada di atas atau dibawah suatu nilai tertentu.
Distribusi frekuensi kumulatif terbagi 2 yaitu :
1). Distribusi frekuensi kumulatif kurang dari adalah suatu total frekuensi dari semua nilai-nilai yang lebih kecil dari tepi bawah kelas pada masing-masing interval kelasnya.
2). Distribusi frekuensi kumulatif lebih dari adalah suatu total frekuensi dari semua nilai-nilai yang lebih besar dari tepi bawah kelas pada masing-masing interval kelasnya.
b. Distribusi Frekuensi Relatif
adalah perbandingan dari frekuensi masing - masing kelas dan jumlah frekuensi seluruhnya yang dinyatakan dalam persen.
Rumus = Fi % / Fn
Ukuran Gejala Pusat Data yang Belum di Kelompokkan
a. Rata – Rata Hitung
Rata-rata hitung adalah nilai yang mewakili sekelompok data.
RH = Fi . Xi / Fi = (F1 . X1 + F2 . X2............Fk . Xk / F1 + F2 ...........Fk)
Fi = frekuensi
Xi = titik tengah
b. Rata – Rata ukur
Rata-rata Ukur/Geometri dari sejumlah N nilai data adalah akar
pangkat N dari hasil kali masing-masing nilai dari kelompok
tersebut.
G = NÖ X1. X2 . … XN atau
log G = (Σ log Xi) / N
c. Rata – Rata Harmonis
Rata-rata Harmonis dari seperangkat data X1, X2, …, XN adalah kebalikan
Rata-rata hitung dari kebalikan nilai-nilai data.
RH = N
Σ (1 / Xi )
d. Median
Median (Me) adalah nilai data yang terletak di tengah-tengah suatu data yang diurutkan (data terurut).
Median terbagi 2 yaitu Median(Me) data tunggal dan Median(Me) data berkelompok :
1) Median(Me) data tunggal
a) Jika banyak data ganjil maka :
Me = data ke- n +1
2
b) Jika banyak data genap maka:
Me = data ke- n/2 + data ke – (n/2 +1 )
2
2) Median(Me) data berkelompok
Me = L + (1/2.n –FkMe).p
FMe
Kuartil,Desil,Persentil
a) Kuartil
Pada prinsipnya, pengertian kuartil sama dengan median. Perbedaanya hanya terletak pada banyaknya pembagian kelompok data. Median membagi kelompok data atas 2 bagian, sedangkan kuartil membagi kelompok data atas 4 bagian yang sama besar, sehingga akan terdapat 3 kuartil yaitu kuartil ke-1, kuartil ke-2 dan kuartil ke-3, dimana kuartil ke-2 sama dengan median:
1).Kuartil pertama/bawah (Q1)
Q1 membagi data terurut menjadi ¼ bagian dan ¾ bagian
· Data ke- n+1/4 ,untuk n ganjil
· Data ke- n+2/4 ,untuk n genap
2).Kuartil kedua/tengah(Q2)
Q2 membagi data terurut menjadi 2/4 atau ½ bagian,Dengan kata lain,Q2 merupakan median data.
· Data ke-n+1 / 2 , untuk n ganjil
· Data ke- (n/2 )+data ke-( (n/2 )+ 1 ) / 2 untuk n genap
3).Kuartil ketiga/atas (Q3)
Q3 membagi data terurut menjadi ¾ bagian dan ¼ bagian.
· Data ke- (3(n+1) )/ 4 ,untuk n ganjil
· Data ke- (3n + 2 ) / 4 ,untuk n genap
b).Desil
Desil adalah Fraktil yang membagi seperangkat data menjadi sepuluh
bagian yang sama.
Desil : Di = nilai yang ke i(n+1) / 10 , i = 1, 2, …, 9
c).Persentil
Persentil adalah Fraktil yang membagi seperangkat data menjadi seratus
bagian yang sama.
Persentil : Pi = nilai yang ke i(n+1) / 100 , i = 1, 2, …, 99
Menentukan Ukuran Statistik Deskriptif Dengan Excel
Langkah-langkahnya:
1. Masukkan data pada range ( A1 : A20)
2. Pilih menu Data pada menu utama
3. Pilih Data Analysis
4. Pilih Deskriptive Statistics pada kotak Analysis
Tools lalu klik OK
Ketika Box Dialog muncul:
_ Pada kotak Input Range, Sorot pada sel A1…A12
_ Pada kotak Output Range , Klik pada sel C2
_ Berikan tanda check pada Summary Statistics ,
kemudian klik OK







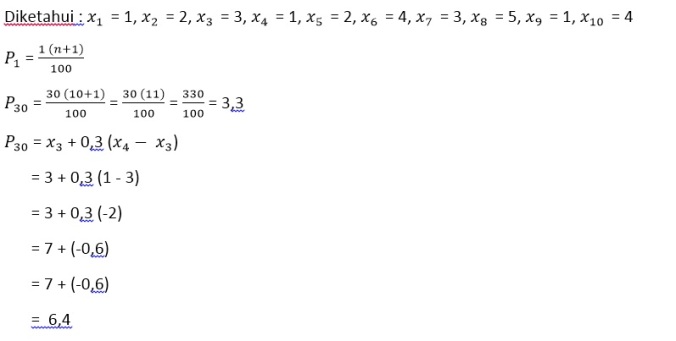
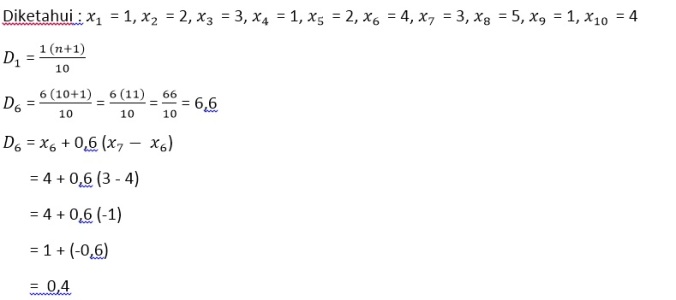
Landasan Teori
Pengertian Distribusi Frekuensi
Distribusi frekuensi adalah suatu bentuk penyusunan data yang teratur dengan menggolongkan besar atau kecilnya data. Distribusi frekuensi umumnya disajikan dalam daftar yang berisi kelas interval dan jumlah objek (frekuensi) yang termasuk dalam kelas interval tersebut.
Fungsi distribusi frekuensi adalah mengatur data mentah (belum dikelompokkan) ke dalam bentuk yang rapi tanpa mengurangi data yang ada.
Istilah – istilah dalam distribusi frekuensi adalah :
- Kelas
- Batas Kelas
- Tepi Kelas
- Interval Kelas
- Titik Tengah
Contoh Kasus Distribusi Frekuensi
Berikut ini adalah data jumlah pendidik kependidikan menurut usia
27 54
27
28
28
22 45
37
50
38
53 48
55
42
44
40 26
31
26
42
36 42
27
53
36
25 25
24
46
43
54 42
49
35
48
32
Berikut ini cara untuk menggunakan analisis manual :
a) Mengurutkan data
b) Menentukan Range
c) Menentukan Banyaknya Kelas
d) Menentukan Panjang Interval Kelas
e) Menentukan Batas – batas Kelas
f) Menentukan Titik Tengah
a).Mengurutkan Data
22 24 25 25 26
26 26 27 27 27
28 31 32 35 36
36 37 38 40 42
42 42 42 43 44
45 46 48 48 49
50 53 53 54 54
55
b)Menentukan Range (R)
Range adalah selisih antara nilai terbesar dengan nilai terkecil.
Rumus Range adalah :
R = Xmax - Xmin
= 55 – 22
= 33
c). Mencari banyaknya kelas menggunakan rumus Sturges
Kelas adalah penggolongan data yang dibatasi dengan nilai terendah dan nilai tertinggi yang masing - masing dinamakan batas kelas.
K = 1 + 3,3 log N
= 1 + 3,3 log 36
= 1 + 5,13
= 6,13 di bulatkan 7
Jadi banyak kelas = 7
d).Menentukan panjang interval kelas (I)
Interval kelas adalah lebar dari sebuah kelas dan dihitung dari perbedaan antara kedua tepi kelasnya.
I = R / K
= 33 / 7
= 4,71 di bulatkan 5
Jadi nilai interval kelasnya = 5
e).Menentukan Batas Kelas
Batas kelas terbagi menjadi 2 yaitu :
1.Batas bawah kelas (bbk),yaitu nilai data yang di tulis untuk setiap kelas interval
2.Batass atas kelas (bak), yaitu nilai data yang terletak disebelah kanan untuk setiap kelas interval
Contoh ; Misalkan salah satu data Pendidik Kependidikan menurut usia adalah = 22 - 27
Kesimpulan ; Batas bawah kelas = 22
Batas atas kelas = 27
F ).Menentukan Tepi Kelas
Tepi kelas terbagi menjadi dua yaitu :
1.Tepi bawah kelas (tbk) : Batas bawah kelas di kurangi ketelitian data (0,5)
Ø Rumus tbk = bbk – 0,5(skala terkecil)
2.Tepi atas kelas (tak) : Batas atas kelas ditambah ketelitian data (0,5)
Ø Rumus tak = bak + 0,5 (skala terkecil)
g ).Menentukan titik tengah
Titik tengah yaitu setengah kali jumlah batas bawah dan batas atas kelas.
Rumus ½ * (bak + bbk)
Contoh ; data = 22 – 27
Xi = ½ * (22 + 27)
= 24,5
Jenis-jenis Distribusi Frekuensi
a.Distribusi Frekuensi Kumulatif
adalah suatu daftar yang memuat frekuensi – frekuensi kumulatif, jika ingin mengetahui banyaknya observasi yang ada di atas atau dibawah suatu nilai tertentu.
Distribusi frekuensi kumulatif terbagi 2 yaitu :
1). Distribusi frekuensi kumulatif kurang dari adalah suatu total frekuensi dari semua nilai-nilai yang lebih kecil dari tepi bawah kelas pada masing-masing interval kelasnya.
2). Distribusi frekuensi kumulatif lebih dari adalah suatu total frekuensi dari semua nilai-nilai yang lebih besar dari tepi bawah kelas pada masing-masing interval kelasnya.
b. Distribusi Frekuensi Relatif
adalah perbandingan dari frekuensi masing - masing kelas dan jumlah frekuensi seluruhnya yang dinyatakan dalam persen.
Rumus = Fi % / Fn
Ukuran Gejala Pusat Data yang Belum di Kelompokkan
a. Rata – Rata Hitung
Rata-rata hitung adalah nilai yang mewakili sekelompok data.
RH = Fi . Xi / Fi = (F1 . X1 + F2 . X2............Fk . Xk / F1 + F2 ...........Fk)
Fi = frekuensi
Xi = titik tengah
b. Rata – Rata ukur
Rata-rata Ukur/Geometri dari sejumlah N nilai data adalah akar
pangkat N dari hasil kali masing-masing nilai dari kelompok
tersebut.
G = NÖ X1. X2 . … XN atau
log G = (Σ log Xi) / N
c. Rata – Rata Harmonis
Rata-rata Harmonis dari seperangkat data X1, X2, …, XN adalah kebalikan
Rata-rata hitung dari kebalikan nilai-nilai data.
RH = N
Σ (1 / Xi )
d. Median
Median (Me) adalah nilai data yang terletak di tengah-tengah suatu data yang diurutkan (data terurut).
Median terbagi 2 yaitu Median(Me) data tunggal dan Median(Me) data berkelompok :
1) Median(Me) data tunggal
a) Jika banyak data ganjil maka :
Me = data ke- n +1
2
b) Jika banyak data genap maka:
Me = data ke- n/2 + data ke – (n/2 +1 )
2
2) Median(Me) data berkelompok
Me = L + (1/2.n –FkMe).p
FMe
Kuartil,Desil,Persentil
a) Kuartil
Pada prinsipnya, pengertian kuartil sama dengan median. Perbedaanya hanya terletak pada banyaknya pembagian kelompok data. Median membagi kelompok data atas 2 bagian, sedangkan kuartil membagi kelompok data atas 4 bagian yang sama besar, sehingga akan terdapat 3 kuartil yaitu kuartil ke-1, kuartil ke-2 dan kuartil ke-3, dimana kuartil ke-2 sama dengan median:
1).Kuartil pertama/bawah (Q1)
Q1 membagi data terurut menjadi ¼ bagian dan ¾ bagian
· Data ke- n+1/4 ,untuk n ganjil
· Data ke- n+2/4 ,untuk n genap
2).Kuartil kedua/tengah(Q2)
Q2 membagi data terurut menjadi 2/4 atau ½ bagian,Dengan kata lain,Q2 merupakan median data.
· Data ke-n+1 / 2 , untuk n ganjil
· Data ke- (n/2 )+data ke-( (n/2 )+ 1 ) / 2 untuk n genap
3).Kuartil ketiga/atas (Q3)
Q3 membagi data terurut menjadi ¾ bagian dan ¼ bagian.
· Data ke- (3(n+1) )/ 4 ,untuk n ganjil
· Data ke- (3n + 2 ) / 4 ,untuk n genap
b).Desil
Desil adalah Fraktil yang membagi seperangkat data menjadi sepuluh
bagian yang sama.
Desil : Di = nilai yang ke i(n+1) / 10 , i = 1, 2, …, 9
c).Persentil
Persentil adalah Fraktil yang membagi seperangkat data menjadi seratus
bagian yang sama.
Persentil : Pi = nilai yang ke i(n+1) / 100 , i = 1, 2, …, 99
Menentukan Ukuran Statistik Deskriptif Dengan Excel
Langkah-langkahnya:
1. Masukkan data pada range ( A1 : A20)
2. Pilih menu Data pada menu utama
3. Pilih Data Analysis
4. Pilih Deskriptive Statistics pada kotak Analysis
Tools lalu klik OK
Ketika Box Dialog muncul:
_ Pada kotak Input Range, Sorot pada sel A1…A12
_ Pada kotak Output Range , Klik pada sel C2
_ Berikan tanda check pada Summary Statistics ,
kemudian klik OK
Contoh soal:
- Menghitung Rata-Rata Hitung
2 . Mencari Rata – Rata ukur
. 
3. Mencari Rata-Rata Harmonis
4. Mencari Rata-Rata Tertimbang
5. Menghitung Median Ganjil
6.Menghitung Median Genap
7. Mencari Modus
8. Mencari Kuartil 1, 2 dan 3
9. Mencari Persentil Ke 30
10. Mencari Desil ke 6
Mengenal Distribusi Frekuensi
DISTRIBUSI FREKUENSI: PENJELESAN DAN CONTOH SOAL
Oleh: Rachmat Ferdianto
Distribusi Frekuensi: Penjelesan dan Contoh Soal – Pada pertemuan ketiga mata kuliah “Statistik” kali ini kita akan membahas mengenai distribusi frekuensi lengkap dengan contoh soalnya. Sebelumnya saya sangat berterima kasih kepada ibu Suri Amelia selaku dosen mata kuliah ini yang telah memberikan materi dengan sangat jelas dan mudah dimengerti. Tapi saya agak kecewa karena pada pertemuan ke tiga kelas kemarin saya gak bisa mengikuti kuis karena ada halangan :'(.
Ok, langsung saja kita kematerinya!
Penjelasan dan Contoh Soal Distribusi Frekuensi
Distribusi Frekuensi
Distribusi frekuensi adalah suatu cara untuk menyusun data baik yang bersifat diskrit / utuh maupun data yang bersifat kontinyu / tidak utuh dengan memasukkan data ke dalam kelas – kelas interval dengan tujuan agar mudah dipahami, dianalisis, dan disimpulkan.
Aturan Sturges
1. Menentukan besarnya range, merupakan selisih antara nilai tertinggi dan nilai terendah dari suatu distribusi data (raw data).
Rumus:
r = a – b
Keterangan:
r = Range
a = Nilai tertinggi
b = Nilai terendah
2. Menentukan banyaknya kelas interval / kelompok interval yang dapat dibentuk dari suatu distribusi data.
Rumus:
K = 1 + 3.332 Log N
Keterangan:
K = Kelas interval / kelompok interval
N = Jumlah frekuensi / distribusi data
3. Menentukan besarnya interval.
Rumus:
i = r / k
Keterangan:
i = Interval
r = Range
K = Kelas /kelompok interval
Frekuensi Kumulatif
Frekuensi Kumolatif adalah frekuensi pada setiap kelas interval dijumlahkan dengan seluruh frekuensi pada kelas – kelas interval sebelumnya.
Frekuensi Relatif
Frekuensi Relatif adalah perbandingan antara frekuensi pada setiap kelas interval dengan jumlah frekuensi secara keseluruhan.
Grafik Histogram
Grafik Histogram adalah suatu grafik yang menggambarkan frekuensi dari setiap kelompok data atau kelompok interval yang berbentuk balok atau persegi empat.
Grafik Polygon
Grafik Polygon adalah grafik distribusi frekuensi dalam bentuk garis yang menghubungkan titik – titik tengah selisih frekuensi pada setiap kelompok interval pada grafik histograf.
Contoh Soal
Susunlah tabel distribusi frekuensi dari distribusi nilai ujian statistik ekonomi I dari 76 orang mahasiswa!
Raw Data:
60 50 60 75 60 55 80 60 50 90
50 65 70 80 70 40 50 60 45 45
40 45 60 70 70 80 90 80 75 60
50 45 40 50 60 80 60 60 70 40
75 70 80 70 60 50 60 70 85 85
60 50 45 50 60 70 70 80 90 85
60 80 60 50 70 60 70 60 80 60
75 60 50 50 60 65
Jawaban
1. Ubah menjadi Array Data:
Jawab:
40 40 40 40 45 45 45 45 45 50
50 50 50 50 50 50 50 50 50 50
50 55 60 60 60 60 60 60 60 60
60 60 60 60 60 60 60 60 60 60
60 60 60 65 65 70 70 70 70 70
70 70 70 70 70 70 70 75 75 75
75 80 80 80 80 80 80 80 80 80
85 85 85 90 90 90
2. Selesaikan Aturan Sturges
Jawab:
1. r = a – b
= 90 – 40
= 50
2. K = 1 + 3.332 Log N
= 1 + 3.332 Log 76
= 1 + 3.332 (1.88)
= 1 + 6.266
= 7.266
= 8
3. i = r / k
= 50 / 8
= 6.25
= 7
Catatan: Dalam aturan sturges, bila hasilnya dalam bentuk koma, misalnya 7.266 maka dibulatkan menjadi 8 atau 6.5 dibulatkan jadi 7.
3. Buat Tabel Distribusi Frekuensi
Jawab:
Tabel Distribusi Frekuensi
No
Nilai
Frekuensi (F)
Frekuensi Kumulatif
Frekuensi Relatif
1
40 – 46
9
9
0.11
2
47 – 53
12
21
0.15
3
54 – 60
22
43
0.28
4
61 – 67
2
45
0.02
5
68 – 74
12
57
0.15
6
75 – 81
13
70
0.17
7
82 – 88
3
73
0.03
8
89 – 95
3
76
0.03
Jumlah
76
0.94
Keterangan:
1. Kolom nilai disebut Interval. Tadi sudah dicari berapa intervalnya yaitu 7. Jadi, data setiap baris pada kolom nilai harus berjumlah 7. Misalnya, 40 – 46 jumlahnya ada 7 (40, 41, 42, 43, 44, 45, 46)
2. Frekuensi: berapa kali muncul data pada kolom nilai. Misalnya, 40 – 46 (lihat array data yang telah kita susun tadi), angka 40 muncul sebanyak 4 kali dan angka 45 muncul sebanyak 5 kali. Jadi, frekuensinya adalah 9
3. Frekuensi kumulatif: lihat penjelasan sebelumnya (Frekuensi Kumolatif adalah frekuensi pada setiap kelas interval dijumlahkan dengan seluruh frekuensi pada kelas – kelas interval sebelumnya). Misalnya, dari tabel di atas kiat ambil Frekuensinya 22. Jadi, frekuensi kumulatifnya adalah 22 + 21 = 43.
4. frekuensi relatif: membandingkan / membagi frekuensi setiap kelas dengan jumlah frekuensi secara keseluruhan. Misalnya, dari tabel kita ambil frekuensinya 9, jadi frekuensi relatifnya adalah 9 / 76 = 0.11
4. Gambarkan Grafik Histogram dan Polygon
Jawab:
Note: Maaf gambarnya jelek dan kualitas kamera gak bagus 😀
Gambar Grafik Histogram dan Polygon
Keterangan: Gambar berbentuk grafik persegi panjang tersebut disebut grafik histogram dan gambar berbentuk garis yang menghubungkan titk tengah setiap grafik disebut grafik polygon.
Catatan:
Jika ada yang kebingungan cara mencari Log 76 dari soal di atas, berikut ini akan saya share hasil logaritma 1 – 100.
1 (0.0000) |51 (1.7076)
2 (0.3010) |52 (1.7160)
3 (0.4771) |53 (1.7243)
4 (0.6021) |54 (1.7324)
5 (0.6990) |55 (1.7404)
6 (0.7782) |56 (1.7482)
7 (0.8451) |57 (1.7559)
8 (0.9031) |58 (1.7634)
9 (0.9542) |59 (1.7709)
10 (1.0000) |60 (1.7782)
11 (1.0414) |61 (1.7853)
12 (1.0792) |62 (1.7924)
13 (1.1139) |63 (1.7993)
14 (1.1461) |64 (1.8062)
15 (1.1761) |65 (1.8129)
16 (1.2041) |66 (1.8195)
17 (1.2304) |67 (1.8261)
18 (1.2553) |68 (1.8325)
19 (1.2788 ) |69 (1.8388 )
20 (1.3100) |70 (1.8451)
21 (1.3222) |71 (1.8513)
22 (1.3424) |72 (1.8573)
23 (1.3617) |73 (1.8633)
24 (1.3802) |74 (1.8692)
25 (1.3979) |75 (1.8751)
26 (1.4150) |76 (1.8808 )
27 (1.4314) |77 (1.8865)
28 (1.4472) |78 (1.8921)
29 (1.4624) |79 (1.8976)
30 (1.4771) |80 (1.9031)
31 (1.4914) |81 (1.9085)
32 (1.5051) |82 (1.9138 )
33 (1.5185) |83 (1.9191)
34 (1.5315) |84 (1.9243)
35 (1.5441) |85 (1.9294)
36 (1.5563) |86 (1.9345)
37 (1.5682) |87 (1.9395)
38 (1.5798 ) |88 (1.9445)
39 (1.5911) |89 (1.9494)
40 (1.6021) |90 (1.9542)
41 (1.6128 ) |91 (1.9590)
42 (1.6232) |92 (1.9638 )
43 (1.6335) |93 (1.9685)
44 (1.6435) |94 (1.9731)
45 (1.6532) |95 (1.9777)
46 (1.6628 ) |96 (1.9823)
47 (1.6721) |97 (1.9868 )
48 (1.6812) |98 (1.9912)
49 (1.6902) |99 (1.9956)
50 (1.6990) |100 (2.0000)
Demikian pembahasan materi Distribusi Frekuensi: Penjelesan dan Contoh Soal dan semoga contoh soal yang admin berikan mudah dipahami. Silahkan gunakan kolom komentar untuk bertanya.
Oleh: Rachmat Ferdianto
Distribusi Frekuensi: Penjelesan dan Contoh Soal – Pada pertemuan ketiga mata kuliah “Statistik” kali ini kita akan membahas mengenai distribusi frekuensi lengkap dengan contoh soalnya. Sebelumnya saya sangat berterima kasih kepada ibu Suri Amelia selaku dosen mata kuliah ini yang telah memberikan materi dengan sangat jelas dan mudah dimengerti. Tapi saya agak kecewa karena pada pertemuan ke tiga kelas kemarin saya gak bisa mengikuti kuis karena ada halangan :'(.
Ok, langsung saja kita kematerinya!
Penjelasan dan Contoh Soal Distribusi Frekuensi
Distribusi Frekuensi
Distribusi frekuensi adalah suatu cara untuk menyusun data baik yang bersifat diskrit / utuh maupun data yang bersifat kontinyu / tidak utuh dengan memasukkan data ke dalam kelas – kelas interval dengan tujuan agar mudah dipahami, dianalisis, dan disimpulkan.
Aturan Sturges
1. Menentukan besarnya range, merupakan selisih antara nilai tertinggi dan nilai terendah dari suatu distribusi data (raw data).
Rumus:
r = a – b
Keterangan:
r = Range
a = Nilai tertinggi
b = Nilai terendah
2. Menentukan banyaknya kelas interval / kelompok interval yang dapat dibentuk dari suatu distribusi data.
Rumus:
K = 1 + 3.332 Log N
Keterangan:
K = Kelas interval / kelompok interval
N = Jumlah frekuensi / distribusi data
3. Menentukan besarnya interval.
Rumus:
i = r / k
Keterangan:
i = Interval
r = Range
K = Kelas /kelompok interval
Frekuensi Kumulatif
Frekuensi Kumolatif adalah frekuensi pada setiap kelas interval dijumlahkan dengan seluruh frekuensi pada kelas – kelas interval sebelumnya.
Frekuensi Relatif
Frekuensi Relatif adalah perbandingan antara frekuensi pada setiap kelas interval dengan jumlah frekuensi secara keseluruhan.
Grafik Histogram
Grafik Histogram adalah suatu grafik yang menggambarkan frekuensi dari setiap kelompok data atau kelompok interval yang berbentuk balok atau persegi empat.
Grafik Polygon
Grafik Polygon adalah grafik distribusi frekuensi dalam bentuk garis yang menghubungkan titik – titik tengah selisih frekuensi pada setiap kelompok interval pada grafik histograf.
Contoh Soal
Susunlah tabel distribusi frekuensi dari distribusi nilai ujian statistik ekonomi I dari 76 orang mahasiswa!
Raw Data:
60 50 60 75 60 55 80 60 50 90
50 65 70 80 70 40 50 60 45 45
40 45 60 70 70 80 90 80 75 60
50 45 40 50 60 80 60 60 70 40
75 70 80 70 60 50 60 70 85 85
60 50 45 50 60 70 70 80 90 85
60 80 60 50 70 60 70 60 80 60
75 60 50 50 60 65
Jawaban
1. Ubah menjadi Array Data:
Jawab:
40 40 40 40 45 45 45 45 45 50
50 50 50 50 50 50 50 50 50 50
50 55 60 60 60 60 60 60 60 60
60 60 60 60 60 60 60 60 60 60
60 60 60 65 65 70 70 70 70 70
70 70 70 70 70 70 70 75 75 75
75 80 80 80 80 80 80 80 80 80
85 85 85 90 90 90
2. Selesaikan Aturan Sturges
Jawab:
1. r = a – b
= 90 – 40
= 50
2. K = 1 + 3.332 Log N
= 1 + 3.332 Log 76
= 1 + 3.332 (1.88)
= 1 + 6.266
= 7.266
= 8
3. i = r / k
= 50 / 8
= 6.25
= 7
Catatan: Dalam aturan sturges, bila hasilnya dalam bentuk koma, misalnya 7.266 maka dibulatkan menjadi 8 atau 6.5 dibulatkan jadi 7.
3. Buat Tabel Distribusi Frekuensi
Jawab:
Tabel Distribusi Frekuensi
No
Nilai
Frekuensi (F)
Frekuensi Kumulatif
Frekuensi Relatif
1
40 – 46
9
9
0.11
2
47 – 53
12
21
0.15
3
54 – 60
22
43
0.28
4
61 – 67
2
45
0.02
5
68 – 74
12
57
0.15
6
75 – 81
13
70
0.17
7
82 – 88
3
73
0.03
8
89 – 95
3
76
0.03
Jumlah
76
0.94
Keterangan:
1. Kolom nilai disebut Interval. Tadi sudah dicari berapa intervalnya yaitu 7. Jadi, data setiap baris pada kolom nilai harus berjumlah 7. Misalnya, 40 – 46 jumlahnya ada 7 (40, 41, 42, 43, 44, 45, 46)
2. Frekuensi: berapa kali muncul data pada kolom nilai. Misalnya, 40 – 46 (lihat array data yang telah kita susun tadi), angka 40 muncul sebanyak 4 kali dan angka 45 muncul sebanyak 5 kali. Jadi, frekuensinya adalah 9
3. Frekuensi kumulatif: lihat penjelasan sebelumnya (Frekuensi Kumolatif adalah frekuensi pada setiap kelas interval dijumlahkan dengan seluruh frekuensi pada kelas – kelas interval sebelumnya). Misalnya, dari tabel di atas kiat ambil Frekuensinya 22. Jadi, frekuensi kumulatifnya adalah 22 + 21 = 43.
4. frekuensi relatif: membandingkan / membagi frekuensi setiap kelas dengan jumlah frekuensi secara keseluruhan. Misalnya, dari tabel kita ambil frekuensinya 9, jadi frekuensi relatifnya adalah 9 / 76 = 0.11
4. Gambarkan Grafik Histogram dan Polygon
Jawab:
Note: Maaf gambarnya jelek dan kualitas kamera gak bagus 😀
Gambar Grafik Histogram dan Polygon
Keterangan: Gambar berbentuk grafik persegi panjang tersebut disebut grafik histogram dan gambar berbentuk garis yang menghubungkan titk tengah setiap grafik disebut grafik polygon.
Catatan:
Jika ada yang kebingungan cara mencari Log 76 dari soal di atas, berikut ini akan saya share hasil logaritma 1 – 100.
1 (0.0000) |51 (1.7076)
2 (0.3010) |52 (1.7160)
3 (0.4771) |53 (1.7243)
4 (0.6021) |54 (1.7324)
5 (0.6990) |55 (1.7404)
6 (0.7782) |56 (1.7482)
7 (0.8451) |57 (1.7559)
8 (0.9031) |58 (1.7634)
9 (0.9542) |59 (1.7709)
10 (1.0000) |60 (1.7782)
11 (1.0414) |61 (1.7853)
12 (1.0792) |62 (1.7924)
13 (1.1139) |63 (1.7993)
14 (1.1461) |64 (1.8062)
15 (1.1761) |65 (1.8129)
16 (1.2041) |66 (1.8195)
17 (1.2304) |67 (1.8261)
18 (1.2553) |68 (1.8325)
19 (1.2788 ) |69 (1.8388 )
20 (1.3100) |70 (1.8451)
21 (1.3222) |71 (1.8513)
22 (1.3424) |72 (1.8573)
23 (1.3617) |73 (1.8633)
24 (1.3802) |74 (1.8692)
25 (1.3979) |75 (1.8751)
26 (1.4150) |76 (1.8808 )
27 (1.4314) |77 (1.8865)
28 (1.4472) |78 (1.8921)
29 (1.4624) |79 (1.8976)
30 (1.4771) |80 (1.9031)
31 (1.4914) |81 (1.9085)
32 (1.5051) |82 (1.9138 )
33 (1.5185) |83 (1.9191)
34 (1.5315) |84 (1.9243)
35 (1.5441) |85 (1.9294)
36 (1.5563) |86 (1.9345)
37 (1.5682) |87 (1.9395)
38 (1.5798 ) |88 (1.9445)
39 (1.5911) |89 (1.9494)
40 (1.6021) |90 (1.9542)
41 (1.6128 ) |91 (1.9590)
42 (1.6232) |92 (1.9638 )
43 (1.6335) |93 (1.9685)
44 (1.6435) |94 (1.9731)
45 (1.6532) |95 (1.9777)
46 (1.6628 ) |96 (1.9823)
47 (1.6721) |97 (1.9868 )
48 (1.6812) |98 (1.9912)
49 (1.6902) |99 (1.9956)
50 (1.6990) |100 (2.0000)
Demikian pembahasan materi Distribusi Frekuensi: Penjelesan dan Contoh Soal dan semoga contoh soal yang admin berikan mudah dipahami. Silahkan gunakan kolom komentar untuk bertanya.
Rabu, 13 Februari 2019
Belajar Penyajian Data
Penyajian Data: Pengertian, Bentuk, dan Contohnya
Oleh Netijen BerkahDiposting pada 13 Februari 2019
Bentuk Penyajian Data
Penyajian data menjadi sangat penting bagi proses penghitungan statistika penelitian. Baik dalam jenis penelitian kuntitataif ataupun kualitataif perolehanan akan data-data yang akurat diperlukan guna mendapatkan hasil yang sesuai dengan realita sesungguhnya. Oleh karena itulah sebagai penjelasan lebih lanjut, artikel ini mengulas tentang pengertian penyajian data, bentuk, dan contohnya.
Daftar Isi
Penyajian Data
Pengertian Penyajian Data
Bentuk Penyajian Data
Contoh Penyajian Data
Tabel
Grafik/Diagram
Keunggulan Penyajian Data Dalam Bentuk Grafik
Jenis Grafik dalam Penyajian Data
Peta
Penyajian Data
Penyajian data adalah mekanisasi yang dipergunakan dalam sebuah laporan penelitian untuk menyajikan rangkaian angka numeric agar mudah dibaca. Sehingga secara umumnya, data-data penelitian tersebut dapat disajikan kepada khalayak umum dengan sangat mudah.
Pengertian Penyajian Data
Pengertian penyajian data adalah aktivitas yang dilakukan oleh seseorang penelitian, baik individu ataupun berkelompok untuk melengkapi proses pembuatan laporan atas hasil penelitian kuantitatif/kualitataif yang telah dilakukan, sehingga senantianysa bisa dianalisis sesuai dengan standar keilmiahanan.
Bentuk Penyajian Data
Secara umum, pada proses penyajian data yang dilakukan untuk penelitian mengandung 3 jenis karaktristik yang berbeda, diantaranya macam penyajian data yang diperlakukan adalah sebagai berikut;
Tabel
Grafik/diagram
Peta
Contoh Penyajian Data
Memperjelas tentang penjelasan akan soal penyajian data diatas, maka uaraian lebih lanjutnya adalah sebagai berikut;
Tabel
Penyajian data dengan tabel merupakan cara yang paling mudah dilakukan dalam sejumlah penelitian statistika. Penyajian dengan tabel ini biasanya dipergunakan untuk kepentingan analisis perbandingan-perbendaingan yang diperlukan dalam teori penelitian sosial.
Contohnya saja yang tergolong dalam penyajian data bentuk tambel misalnya untuk membandingkan tingkat kepadatan penduduk yang berada di suatu wilayah pada periode waktu tertentu, dengan kepadatan penduduk di wilayah lainnya yang berbeda atau sama. Selengkapnya, baca; Dinamika Penduduk: Pengertian, Faktor, dan Contohnya di Indonesia
Grafik/Diagram
Jenis penyajian data yang dipergunakan dalam grafik atau diagram ini sudah mafhum dilakukan dalam serangkaian penelitian-penelitian sosial ataupun eksperimen, yang secara garis besarnya menjelaskan tentang visualisasi penelitian atau informasi tentang kegiatan secara ringkas, menarik, dan jelas.
Contoh penggunaan dalam penyajian data ini sendiri misalnya saja tentang penggunaan data kependudukan yang dilakukan oleh pemerintah untuk mengukur adanya persebaran penduduk tidak merata yang ada di wilayah dan perwilayahan Indonesia.
Keunggulan Penyajian Data Dalam Bentuk Grafik
Adapun beberapa kelebihan atas penyajian data dalam bentuk diagram atau grafik ini, antara lain adalah sebagai berikut;
Pembaca lebih mudah dalam membandingkan data satu dengan data yang lain,
Dapat menggambarkan data secara seri
Penyajian lebih menarik.
Selain memiliki kelebihan, sistem penghitungan dan penampilan data penelitian dengan grafik mempunyai kelemahan dibandingkan dengan penyajian lainnya. Mislanya saja akan karakteristknya yang terpaparkan hanya pendapatkan sedangkan detai terdapat dalam table. Peristilah ini kerap kalian disebut dengan aprosimatif.
Jenis Grafik dalam Penyajian Data
Adapun secara umum, setidaknya ada tiga macam jenis grafik atau diagram dalam penyajian data. Antara lain adalah sebagai berikut;
Grafik batang (bar graph) adalah grafik dalam penyajian data yang mafhumnya diwakili oleh segi empat berbentuk batang, baik horizontal maupun vertikal
Grafik lingkaran (pie graph) adalah prosesi penyajidan yang dilakukan dengan gambaran lingkaran dengan penjelasan persentase disetiap numeriknya.
Grafik garis (line graph) adalah bentuk penyajian data yang umumnya hanya dilakukan penggabaran dalam garis/titik-titik.
Peta
Bentuk penyajian data selanjutanya yang kerapkali dilakukan oleh para penelitian, bisanya dalam peta atau garis. Jenis data atau informasi ini lebih mengerucut pada data kependudukan yang ditampilkan dalam bentuk peta, oleh lembaga pemerintahan ataupun masyarakat umum.
Alasannya penyajian data peta lebih pada kependudukan lantaran dinilai lebih menarik dan mudah dibaca oleh banyak orang terutama tentang pununjukkan lokasinya. Penyajian data atau informasi penduduk dalam bentuk peta menghasilkan konsep ini misalnya saja dalam syarat peta penduduk. Selengkapnya, baca; Manfaat Peta di Indonesia dalam Berbagai Bidang
Beberapa bentuk simbol ini bahkan bisa digunakan untuk menggambankan kondisi kepadatan penduduk. Misalnya simbol piktorial atau dapat juga dengan arsiran bersifat kuantitatif serta gradasi warna. Pemilihan simbol yang tepat menjadi hal penting dalam penyajian data dengan tujuan agar tidak terjadi kesalahan dalam pembacaan.
Dari serangkaian penjelasan tentang pengertian, jenis penyajian data, dan contohnya diatas. Maka dapatlah disimpulkan bahwa penyajian data penelitian akan lebih mudah dipahami jika ditampilkan dalam bentuk grafik atau diagram.
Diagram yang berbentuk garis biasanya digunakan untuk melihat perkembangan data dalam numerik statistik. Diagram ini memuat data-data yang berkesinambungan atau kontinu seperti contohnya saja penghitungan dalam data jumlah penduduk dari tahun ke tahun.
Demikianlah penjelasan lengkap mengenai pengertian penyajian data, bentuk, dan contohnya. Semoga melalui ulasan ini bisa menambah cakrawala pengetahuan bagi segenap pembaca sekalian, terutama yang mendalami materi tentang penelitian. Trimakasih
Oleh Netijen BerkahDiposting pada 13 Februari 2019
Bentuk Penyajian Data
Penyajian data menjadi sangat penting bagi proses penghitungan statistika penelitian. Baik dalam jenis penelitian kuntitataif ataupun kualitataif perolehanan akan data-data yang akurat diperlukan guna mendapatkan hasil yang sesuai dengan realita sesungguhnya. Oleh karena itulah sebagai penjelasan lebih lanjut, artikel ini mengulas tentang pengertian penyajian data, bentuk, dan contohnya.
Daftar Isi
Penyajian Data
Pengertian Penyajian Data
Bentuk Penyajian Data
Contoh Penyajian Data
Tabel
Grafik/Diagram
Keunggulan Penyajian Data Dalam Bentuk Grafik
Jenis Grafik dalam Penyajian Data
Peta
Penyajian Data
Penyajian data adalah mekanisasi yang dipergunakan dalam sebuah laporan penelitian untuk menyajikan rangkaian angka numeric agar mudah dibaca. Sehingga secara umumnya, data-data penelitian tersebut dapat disajikan kepada khalayak umum dengan sangat mudah.
Pengertian Penyajian Data
Pengertian penyajian data adalah aktivitas yang dilakukan oleh seseorang penelitian, baik individu ataupun berkelompok untuk melengkapi proses pembuatan laporan atas hasil penelitian kuantitatif/kualitataif yang telah dilakukan, sehingga senantianysa bisa dianalisis sesuai dengan standar keilmiahanan.
Bentuk Penyajian Data
Secara umum, pada proses penyajian data yang dilakukan untuk penelitian mengandung 3 jenis karaktristik yang berbeda, diantaranya macam penyajian data yang diperlakukan adalah sebagai berikut;
Tabel
Grafik/diagram
Peta
Contoh Penyajian Data
Memperjelas tentang penjelasan akan soal penyajian data diatas, maka uaraian lebih lanjutnya adalah sebagai berikut;
Tabel
Penyajian data dengan tabel merupakan cara yang paling mudah dilakukan dalam sejumlah penelitian statistika. Penyajian dengan tabel ini biasanya dipergunakan untuk kepentingan analisis perbandingan-perbendaingan yang diperlukan dalam teori penelitian sosial.
Contohnya saja yang tergolong dalam penyajian data bentuk tambel misalnya untuk membandingkan tingkat kepadatan penduduk yang berada di suatu wilayah pada periode waktu tertentu, dengan kepadatan penduduk di wilayah lainnya yang berbeda atau sama. Selengkapnya, baca; Dinamika Penduduk: Pengertian, Faktor, dan Contohnya di Indonesia
Grafik/Diagram
Jenis penyajian data yang dipergunakan dalam grafik atau diagram ini sudah mafhum dilakukan dalam serangkaian penelitian-penelitian sosial ataupun eksperimen, yang secara garis besarnya menjelaskan tentang visualisasi penelitian atau informasi tentang kegiatan secara ringkas, menarik, dan jelas.
Contoh penggunaan dalam penyajian data ini sendiri misalnya saja tentang penggunaan data kependudukan yang dilakukan oleh pemerintah untuk mengukur adanya persebaran penduduk tidak merata yang ada di wilayah dan perwilayahan Indonesia.
Keunggulan Penyajian Data Dalam Bentuk Grafik
Adapun beberapa kelebihan atas penyajian data dalam bentuk diagram atau grafik ini, antara lain adalah sebagai berikut;
Pembaca lebih mudah dalam membandingkan data satu dengan data yang lain,
Dapat menggambarkan data secara seri
Penyajian lebih menarik.
Selain memiliki kelebihan, sistem penghitungan dan penampilan data penelitian dengan grafik mempunyai kelemahan dibandingkan dengan penyajian lainnya. Mislanya saja akan karakteristknya yang terpaparkan hanya pendapatkan sedangkan detai terdapat dalam table. Peristilah ini kerap kalian disebut dengan aprosimatif.
Jenis Grafik dalam Penyajian Data
Adapun secara umum, setidaknya ada tiga macam jenis grafik atau diagram dalam penyajian data. Antara lain adalah sebagai berikut;
Grafik batang (bar graph) adalah grafik dalam penyajian data yang mafhumnya diwakili oleh segi empat berbentuk batang, baik horizontal maupun vertikal
Grafik lingkaran (pie graph) adalah prosesi penyajidan yang dilakukan dengan gambaran lingkaran dengan penjelasan persentase disetiap numeriknya.
Grafik garis (line graph) adalah bentuk penyajian data yang umumnya hanya dilakukan penggabaran dalam garis/titik-titik.
Peta
Bentuk penyajian data selanjutanya yang kerapkali dilakukan oleh para penelitian, bisanya dalam peta atau garis. Jenis data atau informasi ini lebih mengerucut pada data kependudukan yang ditampilkan dalam bentuk peta, oleh lembaga pemerintahan ataupun masyarakat umum.
Alasannya penyajian data peta lebih pada kependudukan lantaran dinilai lebih menarik dan mudah dibaca oleh banyak orang terutama tentang pununjukkan lokasinya. Penyajian data atau informasi penduduk dalam bentuk peta menghasilkan konsep ini misalnya saja dalam syarat peta penduduk. Selengkapnya, baca; Manfaat Peta di Indonesia dalam Berbagai Bidang
Beberapa bentuk simbol ini bahkan bisa digunakan untuk menggambankan kondisi kepadatan penduduk. Misalnya simbol piktorial atau dapat juga dengan arsiran bersifat kuantitatif serta gradasi warna. Pemilihan simbol yang tepat menjadi hal penting dalam penyajian data dengan tujuan agar tidak terjadi kesalahan dalam pembacaan.
Dari serangkaian penjelasan tentang pengertian, jenis penyajian data, dan contohnya diatas. Maka dapatlah disimpulkan bahwa penyajian data penelitian akan lebih mudah dipahami jika ditampilkan dalam bentuk grafik atau diagram.
Diagram yang berbentuk garis biasanya digunakan untuk melihat perkembangan data dalam numerik statistik. Diagram ini memuat data-data yang berkesinambungan atau kontinu seperti contohnya saja penghitungan dalam data jumlah penduduk dari tahun ke tahun.
Demikianlah penjelasan lengkap mengenai pengertian penyajian data, bentuk, dan contohnya. Semoga melalui ulasan ini bisa menambah cakrawala pengetahuan bagi segenap pembaca sekalian, terutama yang mendalami materi tentang penelitian. Trimakasih
Sabtu, 02 Februari 2019
Belajar mudah Statistika
Statistika
Adalah ilmu yang mempelajari bagaimana merencanakan, mengumpulkan, menganalisis, menginterpretasi, dan mempresentasikan data. Singkatnya, statistika adalah ilmu yang berkenaan dengan data.
Apa kegunaan dari statistika?
Statistika banyak diterapkan dalam berbagai disiplin ilmu, baik ilmu-ilmu alam (misalnya astronomi dan biologi maupun ilmu-ilmu sosial (termasuk sosiologi dan psikologi), maupun di bidang bisnis, ekonomi, dan industri.
Digunakan dalam pemerintahan untuk berbagai macam tujuan; sensus penduduk merupakan salah satu prosedur yang paling dikenal.
Aplikasi lainnya yang sekarang popular adalah prosedur jajak pendapat atau polling (misalnya dilakukan sebelum pemilihan umum), serta hitung cepat (perhitungan cepat hasil pemilu) atau quick count. Di bidang komputasi, hal ini dapat pula diterapkan dalam pengenalan pola maupun kecerdasan buatan.
Rumus Statistika Matematika
1. Rumus Rata-rata
Rumus Modus Untuk Data Tunggal
Untuk mencari modus dari data tunggal cukup dengan mencari nilai yang banyak keluar.
contoh ada sebuah data tunggal sebagai berikut 2,3,5,7,3,4,7,8,4,6,4,5,4
dari data tunggal di atas maka modusnya adalah 4 (keluar 4 kali)
contoh ada sebuah data tunggal sebagai berikut 2,3,5,7,3,4,7,8,4,6,4,5,4
dari data tunggal di atas maka modusnya adalah 4 (keluar 4 kali)
Rata-Rata untuk Data Tunggal

Keterangan:
ẋ = mean
n = banyaknya data
xi= nilai data ke-i
ẋ = mean
n = banyaknya data
xi= nilai data ke-i
Rata-Rata untuk Data Bergolong (Berkelompok)

Keterangan:
xi = nilai tengah data ke-i
fi = frekuesni data ke -i
xs = rataan sementara (dipilih pada interval dengan frekuensi terbesar)
di = simpangan ke-i (selisih nilai xi dengan nilai xs)
xi = nilai tengah data ke-i
fi = frekuesni data ke -i
xs = rataan sementara (dipilih pada interval dengan frekuensi terbesar)
di = simpangan ke-i (selisih nilai xi dengan nilai xs)
2. Rumus Median
Median adalah nilai data yang terletak di tengah setelah data diurutkan. Dengan demikian, median membagi data menjadi dua bagian yang sama besar. Median (nilai tengah) disimbolkan dengan Me.
- Median untuk Data Tunggal
1. Jika banyaknya data n ganjil maka median

2. Jika banyaknya n genap maka

- Median untuk data bergolong
Keterangan:Me = median
Tb = tepi bawah kelas median
p = panjang kelas
n = banyak data
F = frekuensi kumulatif sebelum kelas median
f = frekuensi kelas median
Tb = tepi bawah kelas median
p = panjang kelas
n = banyak data
F = frekuensi kumulatif sebelum kelas median
f = frekuensi kelas median
3. Rumus Modus
Modus adalah data yang paling sering muncul atau memiliki frekuensi tertinggi. Modus dilambnagnkan dengan Mo.
- Modus untuk data tunggalModus dari data tunggal adalah data yang paling sering muncul.
- Modus untuk data bergolong
Keterangan :Mo : modus
Tb : tepi bawah kelas modus
p : panjang kelas
d1 : selisih frekuensi kelas modus dengan kelas sebelumnya
d2 : selisih frekuensi kelas modus dengan kelas sesudahnya
2 Jenis statistika matematika
1. Deskriptif
Dengan deskripsi data, misalnya dari menghitung rata-rata dan varians dari data mentah; mendeksripsikan menggunakan tabel-tabel atau grafik sehingga data mentah lebih mudah “dibaca” dan lebih bermakna.
berkenaan dengan bagaimana data dapat digambarkan dideskripsikan) atau disimpulkan, baik secara numerik (misalnya menghitung rata-rata dan deviasi standar) atau secara grafis (dalam bentuk tabel atau grafik), untuk mendapatkan gambaran sekilas mengenai data tersebut, sehingga lebih mudah dibaca dan bermakna.
2. Inferensial
Berkenaan dengan permodelan data dan melakukan pengambilan keputusan berdasarkan analisis data, misalnya melakukan pengujian hipotesis, melakukan estimasi pengamatan masa mendatang (estimasi atau prediksi), membuat permodelan hubungan (korelasi, regresi, ANOVA, deret waktu) dan sebagainya.
Misalnya melakukan pengujian hipotesis, melakukan prediksiobservasi masa depan atau membuat model regresi.

Bean machine atau Quincunx adalah salah satu alat bantu yang bisa dipakai untuk memberikan training statistik adalah Sumber foto: Antoine Taveneaux [CC BY-SA 3.0 or GFDL], via Wikimedia Commons
{kind=link}
Contoh soal statistika matematika dan jawaban
1. Penghasilan rata-rata untuk 6 orang adalah Rp. 4.500,00. Jika datang 1 orang,maka penghasilan rata-rata menjadi Rp. 4.800,00. Penghasilan orang yang baru masuk adalah…
Jawaban: rata-rata penghasilan 6 orang 4.500, maka jumlah penghasilan keenam orang tersebut 4.500 x 6 = 27.000.
Jika datang seorang lagi maka rata-rata penghasilan 7 orang 4.800, maka jumlah penghasilan ketujuh orang tersebut 4.800 x 7 = 33.600
Jika datang seorang lagi maka rata-rata penghasilan 7 orang 4.800, maka jumlah penghasilan ketujuh orang tersebut 4.800 x 7 = 33.600
Sehingga penghasilan orang yang beru masuk adalah 33.600 – 27.000 = 6.600
2. Soal Menentukan Nilai Kuartil Bawah
Kuartil bawah dari data : 5, 5, 7, 7, 6, 8, 7, 8, 9 adalah…
Pembahasan dan jawaban:
Kuartil adalah ukuran yang membagi data menjadi 4 bagian yang sama. Kuartil bawah (Q1) terletak di sebelah kiri median.
Kuartil adalah ukuran yang membagi data menjadi 4 bagian yang sama. Kuartil bawah (Q1) terletak di sebelah kiri median.
Urutan data : 5, 5, 6, 7, 7, 7, 8, 8, 9
⇒ Q1 = (5 + 6)/2
⇒ Q1 = 11/2
⇒ Q1 = 5,5
⇒ Q1 = (5 + 6)/2
⇒ Q1 = 11/2
⇒ Q1 = 5,5
3. Hasil ulangan bidang studi Matematika dari beberapa siswa adalah 8, 10, 4, 5, 7, 3, 9, 8, 7, 10, 8, 5. Median dari data tersebut adalah…
Jawaban: median adalah nilai tengah dari suatu data setelah diurutkan sehingga pada data diatas 3,4,5,5,7,7,8,8,8, 9,10,10.
Mediannya (data ke 6 + data ke 7)/2 = (7 + 8) / 2 = 7,5
Mediannya (data ke 6 + data ke 7)/2 = (7 + 8) / 2 = 7,5
4. Contoh Modus Data Bergolong. Tentukan modus dari data berikut:
| DATA | FREKUENSI |
|---|---|
| 11-20 | 5 |
| 21-30 | 3 |
| 31-40 | 8 |
| 41-50 | 7 |
| 51-60 | 4 |
| 61-70 | 9 |
| Jumlah | 36 |
Jawaban:
Karena kelas dengan frekuensi terbanyak 9 maka modus terletak diantara kelas 51-60; tb=51-0,5=50,5; p=10(11-20); di=9-4=5; F=16.
Karena kelas dengan frekuensi terbanyak 9 maka modus terletak diantara kelas 51-60; tb=51-0,5=50,5; p=10(11-20); di=9-4=5; F=16.
Penyelesaian:

Jadi, modusnya adalah 53,36
5. Soal Menentukan Jangkauan Kuartil Data
Diberikan data sebagai berikut: 85, 80, 82, 81, 83, 86, 88
Jangkauan kuartil atau hamparan dari data di atas adalah…
Diberikan data sebagai berikut: 85, 80, 82, 81, 83, 86, 88
Jangkauan kuartil atau hamparan dari data di atas adalah…
Pembahasan dan jawaban:
Untuk menentukan jangkauan kuartil, datanya harus kita urutkan terlebih dahulu dari terkecil ke terbesar.
Urutan data: 80, 81, 82, 83, 85, 86, 88
Diketahui: Q1 = 81, Q2 = 83, Q3 = 86
Urutan data: 80, 81, 82, 83, 85, 86, 88
Diketahui: Q1 = 81, Q2 = 83, Q3 = 86
Jangkauan kuartil atau hamparan:
⇒ H = Q3 – Q1
⇒ H = 86 – 81
⇒ H = 5
⇒ H = Q3 – Q1
⇒ H = 86 – 81
⇒ H = 5
6. Hitunglah nilai rata-rata dari nilai berbobot di bawah ini.
| xi | fi |
| 17
20
31
39
| 2
5
6
4
|
Penyelesaian:
| xi | fi | fi xi |
| 17
20
31
39
| 2
5
6
4
| 34
100
186
156
|
| 17 | 476 |
∑ƒ i x i = 476
n = ∑ƒ i = 17
x = 476 / 17 = 28
n = ∑ƒ i = 17
x = 476 / 17 = 28
7. Soal Menenetukan Median Data Berdasarkan Tabel
Nilai | 60 | 65 | 70 | 75 | 80 | 85 | 90 | 95 |
Frekuensi | 1 | 4 | 2 | 10 | 11 | 3 | 1 | 1 |
Median dari data di atas adalah…
Pembahasan dan jawaban:
Langkah pertama kita hitung banyak datanya kemudian kita tentukan letak median datanya berdasarkan rumus.
Banyak data:
⇒ n = ∑Frekuensi
⇒ n = 1 + 4 + 2 + 10 + 11 + 3 + 1 + 1
⇒ n = 33
⇒ n = 1 + 4 + 2 + 10 + 11 + 3 + 1 + 1
⇒ n = 33
Letak median:
| ⇒ Letak Me = | n + 1 |
| 2 |
| ⇒ Letak Me = | 33 + 1 |
| 2 |
⇒ Letak Me = 34/2
⇒ Letak Me = 17
⇒ Letak Me = 17
Jadi, median datanya terletak pada data ke-17. Berdasarkan tabel, data ke-17 berada kolom nilai ke-4, dengan nilai 75. Jadi, median datanya adalah 75.
8. Dari 40 orang siswa diambil sampel 9 orang untuk diukur tinggi badannya, diperoleh data berikut:
165, 170, 169, 168, 156, 160, 175, 162, 169.
Hitunglah simpangan baku sampel dari data tersebut.
Jawaban:

Jadi, simpangan bakunya adalah 5,83.
9. Soal Rata-rata Gabungan
Nilai rata-rata Fisika dari 10 murid laki-laki adalah 7,50 sedangkan nilai rata-rata dari 5 murid perempuan adalah 7,00. Jika nilai mereka digabungkan, maka nilai rata-ratanya menjadi…
Pembahasan dan jawaban
Dari soal diketahui:
1). Jumlah murid laki-laki : nL = 10 orang
2). Jumlah murid perempuan : np = 5 orang
3). Nilai rata-rata laki-laki : xL = 7,50
4). Nilai rata-rata perempuan : xp = 7,00
1). Jumlah murid laki-laki : nL = 10 orang
2). Jumlah murid perempuan : np = 5 orang
3). Nilai rata-rata laki-laki : xL = 7,50
4). Nilai rata-rata perempuan : xp = 7,00
Nilai rata-rata gabungan:
| ⇒ xg = | nL.xL + np.xp |
| nL + np |
| ⇒ xg = | 10(7,50) + 5(7,00) |
| 10 + 5 |
| ⇒ xg = | 75 + 35 |
| 15 |
⇒ xg = 110/15
⇒ xg = 7,33
⇒ xg = 7,33
10. Soal Rata-rata Gabungan
Nilai rata-rata dari 14 murid untuk ujian kimia adalah 66,25 sebelum ditambah dengan nilai Michael. Setelah nilai ujian Michael keluar, ternyata nilai rata-ratanya menjadi 65,50. Berapa nilai ujian Michael?
Pembahasan dan jawaban:
Diketahui:
1). Jumlah murid kelompok pertama : n1 = 14 orang
2). Jumlah murid kelompok kedua : n2 = 1 orang
3). Nilai rata-rata pertama : x1 = 66,25
4). Nilai rata-rata gabungan : xg = 65,50
1). Jumlah murid kelompok pertama : n1 = 14 orang
2). Jumlah murid kelompok kedua : n2 = 1 orang
3). Nilai rata-rata pertama : x1 = 66,25
4). Nilai rata-rata gabungan : xg = 65,50
Nilai Michael sama dengan nilai rata-rata kelompok kedua sebab pada kelompok kedua hanya ada satu murid yaitu Michael . Dengan demikian, nilai Michael dapat dihitung dengan rumus rata-rata gabungan:
| ⇒ xg = | n1.x1 + n2.x2 |
| n1 + n2 |
| ⇒ 65,50 = | 14(66,25) + 1 .x2 |
| 14 + 1 |
| ⇒ 65,50 = | 927,5 + x2 |
| 15 |
⇒ 65,50 x 15 = 927,5 + x2
⇒ 982,5 = 927,5 + x2
⇒ x2 = 982,5 – 927,5
⇒ x2 = 55
⇒ Nilai Michael = x2 = 55
⇒ 982,5 = 927,5 + x2
⇒ x2 = 982,5 – 927,5
⇒ x2 = 55
⇒ Nilai Michael = x2 = 55
11. Soal Menentukan Median DataMedian dari data : 5, 6, 6, 8, 7, 6, 8, 7, 6, 9 adalah…
Pembahasan dan jawaban:
Median adalah nilai tengah dari data. Untuk menentukan median, datanya harus diurutkan terlebih dahulu.
Urutan data : 5, 6, 6, 6, 6, 7, 7, 8, 8, 9
Urutan data : 5, 6, 6, 6, 6, 7, 7, 8, 8, 9
Median dari data di atas adalah:
| ⇒ Me = | 6 + 7 |
| 2 |
⇒ Me = 13/2
⇒ Me = 6,5
⇒ Me = 6,5
12. Soal Perbandingan Banyak Data
Nilai rata-rata ujian Matematika di kelas X-A adalah 65. Jika nilai rata-rata untuk murid laki-laki adalah 63 dan nilai rata-rata untuk murid perempuan adalah 70, maka perbandingan banyak murid laki-laki dan murid perempuan di kelas itu adalah…
Pembahasan dan jawaban:
Diketahui:
1). Jumlah murid kelompok pertama : nL = 14 orang
2). Jumlah murid kelompok kedua : nP = 1 orang
3). Nilai rata-rata murid laki-laki : xL = 63
4). Nilai rata-rata murid laki-laki : xL = 70
5). Nilai rata-rata gabungan : xg = 65
2). Jumlah murid kelompok kedua : nP = 1 orang
3). Nilai rata-rata murid laki-laki : xL = 63
4). Nilai rata-rata murid laki-laki : xL = 70
5). Nilai rata-rata gabungan : xg = 65
Perbandingan jumlah laki-laki dan perempuan:
| ⇒ | nL | = | nP |
| xL – xg | xg – xP |
| ⇒ | nL | = | nP |
| 70 – 65 | 65 – 63 |
⇒ nL/nP = 5/2
⇒ nL : nP = 5 : 2
⇒ nL : nP = 5 : 2
13. Diketahui bahwa jika Natasha mendapatkan nilai 75 pada ulangan yang akan datang, maka rata-rata nilai ulangannya 82. Jika Natasha mendapatkan nilai 93, maka rata-rata nilai ulangannya adalah 85. Banyaknya ulangan yang sudah diikuti Natasha adalah….
Jawaban:
Misalkan banyaknya ulangan yang Natasha sudah ikuti adalah  dengan nilai rata-rata
dengan nilai rata-rata  .
.
dengan nilai rata-rata .
Jika mendapat ulangan 75 rata-ratanya menjadi 82:
 \end{aligned}")
Jika mendapat ulangan 93 rata-ratanya menjadi 85:
 \end{aligned}")
Dari persamaan (1) dan (2)

Jawaban : A
catatan :
Rata-rata :
:

Rata-rata
:14. Jacoh telah mengikuti test matematika sebanyak 8 kali dari 12 kali test yang ada dengan nilai rata-rata 6,5. Jika untuk seluruh test, Johny ingin mendapatkan rata-rata nilai minimal 7, maka untuk 4 test yang tersisa, Amir harus mendapatkan nilai rata-rata minimal…
Jawaban:
Johny telah mengikuti 8 kali test ") dengan rata-rata 6,5
dengan rata-rata 6,5 ") . Misalkan nilai rata-rata 4 test selanjutnya
. Misalkan nilai rata-rata 4 test selanjutnya ") mempunyai rata-rata
mempunyai rata-rata  .
.
Maka untuk mendapatkan nilai rata-rata akhir 7") :
:
dengan rata-rata 6,5 . Misalkan nilai rata-rata 4 test selanjutnya mempunyai rata-rata .Maka untuk mendapatkan nilai rata-rata akhir 7
:(6,5)+4(\bar{x}_2)}{12}\\ \bar{x}_2&=8 \end{aligned}")
15. Banyaknya siswa kelas XI di Jakarta adalah m siswa. Mereka mengikuti tes matematika dengan hasil sebagai berikut. Lima siswa memperoleh skor 90, siswa lainnya memperoleh skor minimal 60 dan rata-rata skor semua siswa adalah 70. Nilai  terkecil adalah….
terkecil adalah….
Jawaban:
Rumus: x = Jumlah / banyak
+(m-5)(60)}{m}\\ m&=15 \end{aligned}")
16. Berapa bilangan terbesar yang mungkin, jika rata-rata 20 bilangan bulat non negatif berbeda adalah 20?
Jawaban:
Misalnya bilangan bulat terbesar  , untuk mendapatkan nilai terbesar pilih bilangan lainnya sekecil mungkin
, untuk mendapatkan nilai terbesar pilih bilangan lainnya sekecil mungkin
, untuk mendapatkan nilai terbesar pilih bilangan lainnya sekecil mungkin+P}{20} \\ P &= 400 - (0+1+2+3+ \dots +18) = 400 - \tfrac{18}{2}(0+18) \\ \therefore \: P &= 229 \end{aligned}")
catatan:
Nilai rata-rata

Nilai rata-rata
Deret Aritmatika dengan banyak suku , suku awal  , dan suku akhir
, dan suku akhir 
~}")
, suku awal , dan suku akhir 17. Sebuah himpunan terdiri atas 10 anggota yang semuanya bilangan bulat mempunyai rata-rata, median, modus,serta jangkauan yang sama, yaitu 9. Hasil kali antara bilangan terkecil dan terbesar yang masuk dalam himpunan tersebut adalah….
Jawaban:
Median (nilai tengah) dan rata-rata harus 9, supaya mendapatkan
Dengan memperhatikan rata-rata 9 (jumlah ke 10 data tersebut 90) dan jangkauan (
x[max] terbesar, di sebelah kanan median (setelah diurutkan) nilai datanya dibuat sekecil mungkin kecuali data terbesar (x[max]), dan di sebelah kiri dibuat sebesar mungkin sedemikian rupa supaya menghasilkan nilai hasil kali data terkecil (x[min]) dan terbesar maksimum.Dengan memperhatikan rata-rata 9 (jumlah ke 10 data tersebut 90) dan jangkauan (
nilai x[max]-x[min] = 9), beberapa kemungkinan himpunan bil tersebut8, 8, 8, 8, 9, 9, 9, 9, 9, 17→ tidak memenuhi syarat jumlah data 90
7, 7, 7, 8, 9, 9, 9, 9, 9, 16→
x(min).x(max) = 1126, 7, 8, 8, 9, 9, 9, 9, 9, 15→
x(min).x(max) = 90 (bertambah kecil)
Jadi nilai maksimum dari hasil kali data terbesar
(x[max]) dan terkecil (x[min]) = 112.
Jawaban : B
catatan:
Modus = data yang paling banyak muncul
Median = data tengah
Jangkauan = data terbesar – data terkecil =
Modus = data yang paling banyak muncul
Median = data tengah
Jangkauan = data terbesar – data terkecil =
x[max] - x[min]
Langganan:
Postingan (Atom)